


8.3XML
Die Abkürzung XML steht für eXtensible Markup Language. XML wurde vom WWW-Konsortium entwickelt, beschrieben und standardisiert. Sie ist wie JSON textbasiert, jedoch im Gegensatz dazu eine Metasprache, die als Grundlage für anwendungsspezifische Sprachen dient. XML ist so umfangreich, [Anm.: http://www.w3.org/TR/xml] dass eine detaillierte Darstellung den Umfang dieses Buches sprengen würde, und deshalb stellen wir nur die wichtigsten Elemente vor.
8.3.1XML in Kürze
Der XML-Standard legt verschiedene Elemente für ein Dokument fest. Es kann mit der XML-Deklaration in der ersten Zeile beginnen, die die Version und die Zeichenkodierung des Dokuments festlegt, z. B.:
<?xml version="1.0"?>
<?xml version="1.0" encoding="utf-8"?>
Die Deklaration muss die Versionsangabe enthalten, und wenn die Angabe der Zeichenkodierung oder die komplette Deklaration fehlt, verwendet der Parser UTF-8.
XML und die Zeichenkodierung
Die richtige Zeichenkodierung ist eine häufige Fehlerquelle in XML-Dokumenten, da die Kodierungsangabe in der Deklaration von der tatsächlichen Kodierung des Dokuments abweichen kann. Sie können beispielsweise in der Deklaration utf-8 angeben und das Dokument mit der Kodierung MacRoman abspeichern, oder Sie lassen bei einem Dokument in utf-8 die Deklaration weg. Achten Sie also bei Ihren XML-Dokumenten auf eine korrekte XML-Deklaration, wenn Sie eine andere Zeichenkodierung als UTF-8 verwenden.
Tags
Über Tags stellen Sie die sich aus dem Inhalt ergebende Struktur der Daten dar. Sie haben die Form <Tagname>Inhalt</Tagname> oder <Tagname/>, wobei die Tag?Namen anwendungsspezifisch sind und der Inhalt wieder Tags oder Texte sein können. Außerdem können Tags Attribute enthalten: <Tagname Attribut_1="Wert_1" ... Attribut_n="Wert_n">Inhalt</Tagname> beziehungsweise <Tagname Attribut_1="Wert_1" ... Attribut_n="Wert_n"/>. Ein XML-Dokument enthält genau ein Tag auf der obersten Ebene. Alle weiteren Tags des Dokuments sind in diesem Tag enthalten. Dieses Tag nennt man auch das Wurzelelement des Dokuments. Eine anwendungsspezifische Sprache legt die erlaubten Tags mit den Attributen und deren Verschachtelungsstruktur fest. Beispiel:
<?xml version="1.0" encoding="UTF-8"?>
<users>
<user id="1">
<name>Spiro</name><job>Kellner</job>
</user>
<user id="2">
<name>Tuttle</name><job>Klempner</job>
</user>
<user id="10">
<name>Lowry</name><job>Verwaltungsangestellter</job>
</user>
</users>
Alles hat ein Ende, nur die Wurst hat zwei
In einem gültigen XML-Dokument muss es zu jedem öffnenden Tag auch das entsprechende, schließende Tag auf der gleichen Ebene geben. Ein gültiges HTML-4-Dokument darf beispielsweise
<p>
Mein schönes Fräulein, darf ich wagen,<br>
Meinen Arm und Geleit Ihr anzutragen?<br>
</p>
enthalten. Das ist hingegen kein gültiges XML, da es zu den <br>-Tags jeweils kein schließendes </br> gibt und auch nicht die Kurzform <br/> verwendet wurde.
Ein XML-Dokument können Sie sich auch als Baum [Anm.: http://de.wikipedia.org/wiki/Baum_(Graphentheorie)] vorstellen, in dem die Tags, Texte, Kommentare und Verarbeitungsanweisungen die Knoten sind. Das Wurzelelement des Dokuments ist dabei auch die Wurzel des Baums, und die direkten Unterelemente im Wurzelelement sind die Kinder des Wurzelknotens.
Den Baum zum XML-Dokument aus Listing 8.13 sehen Sie in Abbildung 8.7. Das Wurzelelement <users> hat die beiden direkten Unterelemente <user>, die deswegen am Wurzelknoten hängen. Analog haben diese beiden Elemente wiederum zwei direkte Unterelemente – jeweils <name> und <job> –, die Sie als entsprechende Unterknoten auch im Baum finden. Darunter hängen jeweils die Texte als Blätter.
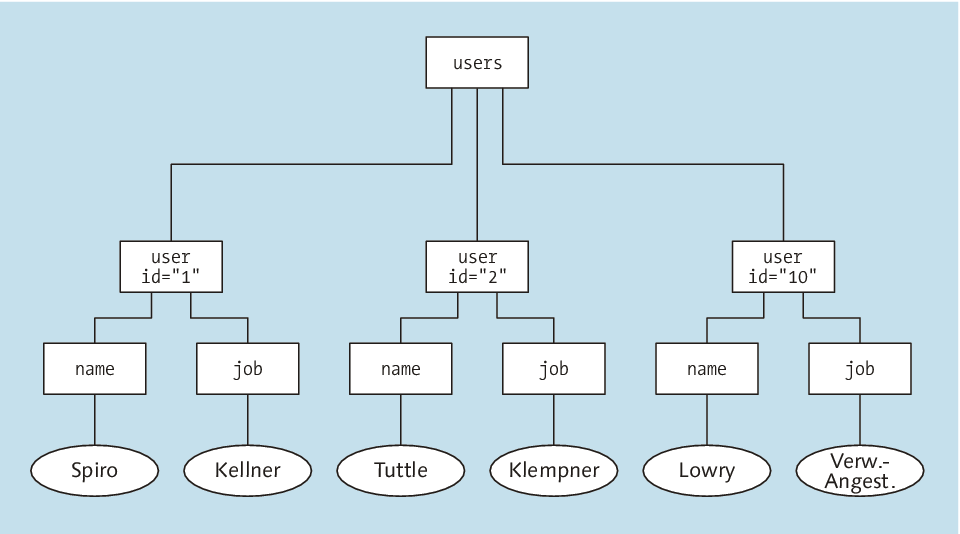
Abbildung 8.7 XML-Dokument in Baumdarstellung
Text
Wie das Beispiel in Listing 8.13 zeigt, kann zwischen den Tags nahezu beliebiger Text stehen. Die Zeichen < und & dürfen allerdings nicht im Text stehen. Sie lassen sich jedoch durch die XML-Entitäten < beziehungsweise & darstellen. Eine Liste aller XML-Entitäten enthält Tabelle 8.4. Der XML-Parser ersetzt die Entitäten durch die entsprechenden Zeichen. Sie bekommen also bei der Verarbeitung die Entitäten nicht zu sehen.
| Zeichen | XML-Entitäten |
|
< |
< |
|
> |
> |
|
& |
& |
|
" |
" |
|
' |
' |
Mit den Entitäten ist es somit möglich, dass ein XML-Dokument weitere XML-Dokumente enthält und der Parser das enthaltene Dokument als Text betrachtet.
<zitat>
<autor>Goethe</autor>
<werk>Faust I</autor>
<text><p>Mein schönes Fräulein, darf ich wagen,<br>
Meinen Arm und Geleit Ihr anzutragen?<br></p></text>
</zitat>
Listing 8.14 XML mit falsch eingebundenem Text
Das Dokument aus Listing 8.14 führt bei einem XML-Parser zum einen zu Fehlern, da die <br>-Tags nicht geschlossen wurden. Zum anderen soll er ja das Zitat als Text liefern, um es beispielsweise in eine HTML-Seite zu integrieren. Dafür müssen Sie die Sonderzeichen also maskieren:
<zitat>
<autor>Goethe</autor>
<werk>Faust I</autor>
<text>
<p>Mein schönes Fräulein, darf ich wagen,<br>
Meinen Arm und Geleit Ihr anzutragen?<br></p>
</text>
</zitat>
Listing 8.15 XML mit richtig eingebundenem Text
Diese Art der Maskierung kann bei längeren Texten allerdings sehr unleserlich werden. Hier hilft die Verwendung von CDATA-Abschnitten, bei denen Sie die Texte jeweils in die Zeichenfolgen <![CDATA[ und ]]> einschließen:
<zitat>
<autor>Goethe</autor>
<werk>Faust I</autor>
<text><![CDATA[
<p>Mein schönes Fräulein, darf ich wagen,<br>
Meinen Arm und Geleit Ihr anzutragen?<br></p>
]]></text>
</zitat>
Listing 8.16 XML mit Text in einem CDATA-Abschnitt
Alles, was zwischen den CDATA-Begrenzern steht, interpretiert der XML-Parser als Text; er ignoriert hier also das p- und die br-Tags.
Kommentare
Kommentare haben die Form <!--Text--> mit beliebigem Text, der jedoch natürlich nicht die Zeichenfolge --> enthalten darf. Sie können Kommentare nahezu beliebig innerhalb von Elementen einfügen.
Verarbeitungsanweisungen
Verarbeitungsanweisungen werden eher selten verwendet und haben die Form <?Name Daten ?>. Mit ihnen lassen sich Hinweise an die Applikationen einfügen, die das XML-Dokument verarbeiten, wobei der Name die Applikation adressiert. Der Inhalt der Daten lässt sich nahezu frei festlegen und hat häufig die Form der Attributlisten analog zu den Tags. Die XML-Deklaration <?xml ... ?> ist übrigens keine Verarbeitungsanweisung, auch wenn sie so aussieht.
Namensräume
Durch XML-Namensräume lassen sich unterschiedliche Anwendungssprachen in einem XML-Dokument mischen, und hierfür gibt es sogar ein eigenes Standardisierungsdokument [Anm.: http://www.w3.org/TR/REC-xml-names] . Um die Tags der verschiedenen Sprachen auseinanderzuhalten, erhalten sie bis auf den Standardnamensraum Präfixe, die Namensraumdeklarationen festlegen. Diese Präfixe dienen jedoch nur dazu, die Schreibweise der Tags zu vereinfachen. Die Identifizierung der Namensräume geschieht immer über einen URI [Anm.: siehe auch http://tools.ietf.org/html/rfc1630] – das ist ein eindeutiger Bezeichner für eine Ressource, wie z. B. URLs, die gerne dafür verwendet werden.
Die Deklaration eines Namensraums geschieht über das Attribut xmlns in einem beliebigen Element, und der Namensraum gilt dann für dieses Element und alle darin enthaltenen Elemente. Auf den Attributnamen xmlns darf optional, durch einen Doppelpunkt getrennt, das Präfix folgen.
<root xmlns="http://www.cocoaneheads.de/example"
xmlns:ref="/reference"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<value xsi:nil=""/>
<ref:reference>
<description>
<html xmlns="http://www.w3.org/1999/xhtml/">
<head>...</head>
<body>...</body>
</html>
</description>
</ref:reference>
</root>
Listing 8.17 Beispiel für XML-Namensräume
Das Beispiel in Listing 8.17 verwendet insgesamt vier unterschiedliche Namensräume, wobei das Dokument jeweils die Namensräume http://www.cocoaneheads.de/example und http://www.w3.org/1999/xhtml als Standardnamensräume verwendet. Also gehören alle Tags ohne Präfix automatisch zu jeweils einem dieser Räume (siehe Tabelle 8.5).
| Tag- bzw. Attributname | Namensraum |
|
root |
|
|
value |
|
|
xsi:nil |
|
|
ref:reference |
/reference |
|
description |
|
|
html |
|
|
head |
|
|
body |
Tabelle 8.5 ordnet den Attributen und Tags aus Listing 8.17 die entsprechenden Namensräume zu. Im Gegensatz zu Tags kommen Attribute mit Präfix allerdings sehr selten vor, da sie die Auswertung beim Parsen erschweren.
Bevor wir auf die Verarbeitung beliebiger Anwendungssprachen durch XML-Parser eingehen, stellen wir Property-Listen vor, die sich auch als XML-Dokumente abspeichern lassen. Für die Verarbeitung stellt das Foundation-Framework Ihnen einen fertigen Parser zur Verfügung.
8.3.2Property-Listen
Apple stellt mit Property-Listen Dokumentenformate mit den notwendigen Werkzeugen bereit, die von ihren Möglichkeiten her JSON sehr stark ähneln. Property-Listen können also ähnliche Daten wie JSON-Dokumente speichern. Dabei dürfen XML-Property-Listen die folgenden Elemente enthalten:
| Datentyp | Tag | Klasse |
|
Boolean |
<false/>, <true/> |
NSNumber |
|
Ganzzahl |
<integer> |
NSNumber |
|
Fließkommazahl |
<real> |
NSNumber |
|
Zeichenkette |
<string> |
NSString |
|
Datum |
<date> |
NSDate |
|
Array |
<array> |
NSArray |
|
Dictionary |
<dict> |
NSDictionary |
|
Binäre Daten |
<data> |
NSData |
Neben den in Tabelle 8.6 aufgeführten Tags gibt es noch <plist>, das als Wurzelelement für die Dokumente dient, und <key> für Schlüssel in Dictionarys. Das Beispiel aus Listing 8.1 sieht als Property-Liste so aus:
<?xml version="1.0" encoding="UTF-8"?>
<plist version="1.0">
<dict>
<key>lottozahlen</key>
<array>
<integer>1</integer>
<integer>2</integer>
<integer>13</integer>
<integer>19</integer>
<integer>27</integer>
<integer>32</integer>
<integer>49</integer>
</array>
<key>zusatzzahl</key>
<integer>22</integer>
<key>gewinner</key>
<array>
<dict>
<key>name</key>
<string>Lieschen Müller</string>
<key>zusatzzahl</key>
<true/>
</dict>
<dict>
<key>name</key>
<string>Gustav Ganz</string>
<key>zusatzzahl</key>
<false/>
</dict>
</array>
</dict>
</plist>
Listing 8.18 Beispiel für eine Property-Liste
Wie Sie anhand der beiden Beispiele aus den Listings sehen, braucht die Property-Liste wesentlich mehr Platz als das JSON-Dokument. Property-Listen können im Gegensatz zu JSON Datums- und Datenobjekte speichern. Das date-Tag enthält das Datum als Text in der Form yyyy-mm-ttThh:mm:ssZ in der Greenwich Mean Time (GMT) oder auch UTC [Anm.: Universal Time Coordonné] . Das heißt, es liegt gegenüber der mitteleuropäischen Zeit eine beziehungsweise zwei Stunden [Anm.: Zur Sommerzeit sind es zwei Stunden und zur Winterzeit eine.] zurück. Der 16. Juni 2012 um 15:59 Uhr und 28 Sekunden (MESZ) sieht in einer XML-Property-Liste also so aus:
<date>2012-06-16T13:59:28Z</date>
Der in Xcode eingebaute Property-List-Editor rechnet das Datum jedoch automatisch in die aktuelle Zeitzone des Rechners um, und er erleichtert Ihnen dadurch die Bearbeitung von Property-Listen. Durch einen Rechtsklick auf die Datei und die Auswahl des Menüpunktes Open As können Sie in Xcode zwischen verschiedenen Darstellungsformen umschalten (siehe Abbildung 8.8), wobei die Property-Listen- und die Sourcecode-Ansicht am wichtigsten sind.
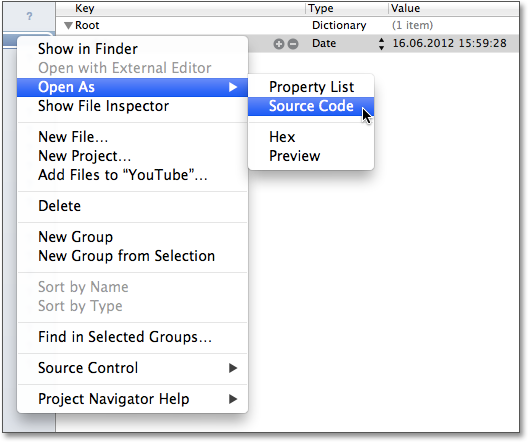
Abbildung 8.8 Darstellung einer Property-Liste in Xcode
Datenobjekte können Sie zwar auch editieren, da es sich jedoch um binäre Daten handelt, ist das in den meisten Fällen nicht sinnvoll. Apple verwendet dafür die Base-64-Kodierung, was dann beispielsweise so aussieht: <data>ByQmBp92AAV3CA==</data>.
Das Lesen und Schreiben von Property-Listen ist relativ einfach, da die Klassen NSArray und NSDictionary es direkt unterstützen. Zum Lesen dienen die Convenience-Konstruktoren arrayWithContentsOfFile: und arrayWithContentsOfURL: von NSArray beziehungsweise dictionaryWithContentsOfFile: und dictionaryWithContentsOfURL: von NSDictionary. Mit folgendem Code kann beispielsweise eine App ihre eigene Info.plist-Datei auslesen:
NSBundle *theBundle = [NSBundle mainBundle];
NSURL *theURL = [theBundle URLForResource:@"Info"
withExtension:@"plist"];
NSDictionary *theDictionary =
[NSDictionary dictionaryWithContentsOfURL:theURL];
Listing 8.19 Auslesen der »Info.plist«
Das Schreiben einer XML-Property-Liste erfolgt jeweils über die Methode writeToFile:atomically: der Klassen NSArray und NSDictionary. Auch hier müssen Sie darauf achten, dass die Objekthierarchie nur aus Objekten mit den in Tabelle 8.6 genannten Klassen besteht; andernfalls liefert die Methode NO zurück und schreibt keine Daten.
Bei der Kommunikation zwischen einem iOS-Gerät und einem Server sind die Deserialisierung von Property-Listen aus NSData-Objekten und die Serialisierung in NSData-Objekte notwendig. Dafür stellt Apple die Klasse NSPropertyListSerialization mit den Methoden dataWithPropertyList:format:options:error: und propertyListWithData:options:format:error: bereit.
Die Methode dataWithPropertyList:format:options:error: wandelt einen Objektbaum, dessen Objekte die in Tabelle 8.6 genannten Klassen haben müssen, in ein Datenobjekt um. Für den Parameter format sollten Sie NSPropertyListXMLFormat_v1_0 verwenden, um ein XML-Dokument zu erhalten, und der Parameter options sollte immer 0 sein. Ein Objekt können Sie also folgendermaßen in eine Property-Liste überführen:
NSError *theError = nil;
NSData *theData = [NSPropertyListSerialization
dataWithPropertyList:theObject
format:NSPropertyListXMLFormat_v1_0
options:0 error:&theError];
Listing 8.20 Umwandlung einer Property-Liste in ein Datenobjekt
Im Gegensatz dazu ist der Formatparameter bei der Methode propertyListWithData:options:format:error: ein Ausgabeparameter, über den Sie das Format des Dokuments im Datenobjekt erfahren. Wenn diese Information Sie nicht interessiert, können Sie dafür auch den Wert NULL verwenden. Über den options-Parameter lässt sich festlegen, ob die Methode unveränderliche oder veränderliche Objekte erzeugen soll. Tabelle 8.7 zeigt eine Übersicht der verfügbaren Optionen und der Klassen der damit erzeugten Objekte.
Property-Listen mit Format
Neben XML unterstützen Property-Listen zwei weitere Formate: das inzwischen veraltete OpenStep-Format und das kompakte Binärformat, das allerdings nicht mit einem Texteditor lesbar ist. Sie können es jedoch mit dem Kommandozeilenprogramm plutil umwandeln; durch plutil -convert format file.plist wandeln Sie die Datei file.plist in das Format format um. Dafür stehen Ihnen die Werte xml1 (XML-Format), binary1 (Binärformat) und json (JSON-Format) zur Verfügung. Aber Achtung: Das Programm verändert die Datei. Wenn Sie sie nicht ändern wollen, sollten Sie sie entweder vorher kopieren und den Aufruf auf der Kopie ausführen oder über den zusätzlichen Schalter -o die Ausgabe umleiten. Beispielsweise zeigt plutil -convert xml1 -o -datei.plist die Datei datei.plist in der Standardausgabe an. Anstelle des Minuszeichens hinter -o für die Standardausgabe können Sie auch einen Dateinamen angeben, um die Ausgabe dorthin umzuleiten
| Option | Verwendete Klassen |
|
NSPropertyListImmutable |
wie in Tabelle 8.6 |
|
NSPropertyListMutable-Containers |
NSData, NSDate, NSNumber, NSData, NSString, NSMutableArray, NSMutableDictionary |
|
NSPropertyListMutable-ContainersAndLeaves |
NSDate, NSNumber, NSMutableData, NSMutableString, NSMutableArray, NSMutableDictionary |
Wenn Sie also eine der beiden letzten Optionen verwenden, können Sie die erzeugten Property-Listen auch verändern. Das Umwandeln eines Datenobjekts in eine unveränderliche Property-Liste sieht beispielsweise so aus:
NSError *theError = nil;
NSPropertyListFormat theFormat;
id theObject = [NSPropertyListSerialization
propertyListWithData:theData
options:NSPropertyListImmutable format:&theFormat
error:&theError];
Listing 8.21 Lesen einer Property-Liste aus einem Datenobjekt
8.3.3SAX
Für die XML-Verarbeitung haben sich die beiden grundsätzlich unterschiedlichen Wege SAX und DOM etabliert. Dabei ist das Simple API for XML (SAX) [Anm.: http://www.saxproject.org] ein De-facto-Standard, der das XML-Dokument als Strom von Ereignissen behandelt. David Megginson hat SAX ursprünglich als ein Java-Framework entwickelt, und inzwischen gibt es Adaptierungen für fast alle Programmiersprachen.
Ein SAX-Parser liest das XML-Dokument ein und ruft für vordefinierte Ereignisse jeweils vordefinierte Methoden auf. Tabelle 8.8 zeigt ein Beispiel-XML-Dokument mit den zugehörigen SAX-Ereignissen.
| XML | SAX-Ereignisse |
|
Start Document |
|
|
<hello xmlns:g="/greetings"> |
Start Namespace |
|
<g:text language="de"> |
Start Element |
|
Hallo Welt |
Characters (ggf.gegebenenfalls mehrmals) |
|
</g:text> |
End Element |
|
<?printer pagebreak?> |
Processing Instruction |
|
<g:text xmlns:m="/markup" |
Start Namespace |
|
Hello <m:u>world</m:u> |
Characters |
|
<m:break/> |
Start Element |
|
</g:text> |
End Element |
|
</hello> |
End Element |
|
End Document |
Wie Sie an dem Beispiel sehen, löst ein Element immer mindestens zwei Ereignisse (Start und Ende) aus. Für jeden deklarierten Namensraum kommen noch einmal zwei Ereignisse hinzu. Bei Text sendet der Parser mindestens ein Ereignis; er kann den Text jedoch auch in mehrere Teile zerlegen und mehrere Ereignisse zu dem Text senden.
Textschnipsel
Die SAX-Implementierung von Apple zerteilt Texte in mehrere Stücke, wenn sie Umlaute enthalten. Zumindest teilt der Parser den Text vor dem ersten Umlaut in zwei Teile. Sie sollten sich also niemals darauf verlassen, die Texte in einem Stück zu erhalten.
Eine SAX-Implementierung legt zu den einzelnen Ereignissen Rückrufmethoden fest, die der Parser bei Auftreten des jeweiligen Ereignisses aufruft. Das Protokoll NSXMLParserDelegate deklariert diese Rückrufmethoden, die Tabelle 8.9 für die wichtigsten Ereignisse auflistet. Im Allgemeinen reicht es für die Verarbeitung aus, diese Methoden zu implementieren. Wenn die XML-Dokumente keinen oder nur einen Namensraum verwenden oder Sie die Namensraumdeklarationen nicht interessieren, können die Methoden für die Behandlung für Beginn und das Ende der Namensräume auch entfallen.
Der erste Parameter für alle Rückrufmethoden ist der Parser – ein Objekt mit der Klasse NSXMLParser. Um die XML-Verarbeitung zu starten, müssen Sie einen Parser erzeugen, ihn konfigurieren und ihm ein Delegate zuweisen. Danach können Sie die Verarbeitung über die Methode parse starten:
NSXMLParser *theParser =
[[NSXMLParser alloc] initWithData:theData];
theParser.shouldProcessNamespaces = YES;
theParser.shouldReportNamespacePrefixes = YES;
theParser.delegate = theDelegate;
[theParser parse];
Listing 8.22 XML-Verarbeitung mit NSXMLParser
Listing 8.22 schaltet zwei Konfigurationsoptionen des Parsers ein. Über die Property shouldProcessNamespaces weisen Sie den Parser an, Ihnen die Namensraumdeklarationen bei den Ereignissen für Start und End Element mitzuteilen. Die Ereignisse für Start und End Namespace erhalten Sie nur, wenn Sie den Wert für die Property shouldReportNamespacePrefixes auf YES setzen.
Ein SAX-Parser in der Praxis
Nach diesen wichtigen Grundlagen soll nun endlich ein praktisches Beispiel folgen. Das Beispielprojekt SiteSchedule ist eine Anwendung für ein fiktives Bauunternehmen, das Arbeitsteams zu verschiedenen Baustellen entsendet. Eine iPhone-App soll nun die Mitarbeiter (z. B. Architekten, Manager) der Firma bei der Betreuung der Teams unterstützen. Sie können über die App nachvollziehen, wo sich die Teams aktuell befinden, welche Aufgaben sie gerade haben und wer die Kontaktpersonen des Teams sind. Die App aktualisiert die Daten über einen Server und speichert sie über Core Data in der iPhone-App.
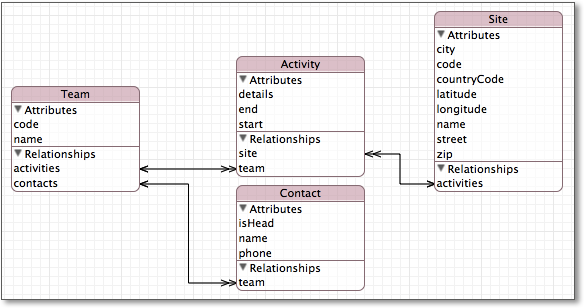
Abbildung 8.9 Das Core-Data-Modell der Beispielapplikation
Projektinformation
Den Quellcode des folgenden Beispiels finden Sie auf der DVD unter Code/Apps/iOS6/SiteSchedule oder im Github-Repository zum Buch im Unterverzeichnis https://github.com/Cocoaneheads/iPhone/tree/Auflage_3/Apps/iOS6/SiteSchedule.
Zu jedem Core-Data-Entitätstyp gibt es ein gleichnamiges [Anm.: In Kleinschreibung] XML-Element, das die Daten einer Entität enthält. Die Attribute der Entitätstypen enthalten diese XML-Elemente entweder als eigene XML-Elemente, XML-Attribute oder als Textinhalt. Insgesamt enthält das XML der App zwölf unterschiedliche Tags. Listing 8.23 enthält ein Beispiel mit allen möglichen Elementen für ein solches XML-Dokument, das im Folgenden zur Veranschaulichung der Funktionsweise dient.
<?xml version="1.0" encoding="UTF-8"?>
<schedule>
<teams>
<team code="100">
<name>Betonbauer</name>
<contact phone="+49 163 1234567"
isHead="YES">Hr. Meier</contact>
</team>
</teams>
<sites>
<site code="10001">
<name>Kölner Dom</name>
<street>Domkloster 4</street>
<city zip="50667">Köln</city>
<countryCode>de</countryCode>
<activities>
<activity team="100" start="2012-03-01 6:00"
end="2012-03-31 12:00">
Stabilisierungsarbeiten</activity>
</activities>
</site>
</sites>
</schedule>
Listing 8.23 XML-Dokument für die Beispielapplikation
Verarbeitung von Textinhalten
Zunächst gibt es eine Reihe attributloser Tags, die nur Text enthalten (z. B. <name>, <street>). Diese Tags enthalten Attributwerte für die umgebenden Objekte. Der XML-Parser kann ein oder mehrere Characters-Ereignisse für den Text in einem Tag senden, was der NSXMLParser auch bei Nicht-ASCII-Zeichen tatsächlich macht. Für die Zeichenkette »Köln« sendet er beispielsweise die Characters-Ereignisse mit den Texten »K« und »öln«.
Diese Eigenschaft lässt sich mit einer veränderlichen Zeichenkette der Klasse NSMutableString abfangen, mit der das Delegate die Bestandteile sukzessive aufsammelt. Die Klasse SiteScheduleParser, die das Parser-Delegate der Beispielapplikation implementiert, besitzt dafür die private Property text, und die Methode parser:foundCharacters: sammelt darin die Zeichen folgendermaßen auf:
- (void)parser:(NSXMLParser *)inParser
foundCharacters:(NSString *)inText {
[self.text appendString:inText];
}
Listing 8.24 Aufsammeln des Textes
Allerdings sollte das Delegate den Inhalt der Zeichenkette immer zu Beginn eines neuen Tags löschen, damit sie nicht noch den Text der vorhergehenden Tags enthält. Das geschieht über die Zeile
[self.text deleteCharactersInRange:
NSMakeRange(0, self.text.length)];
zu Beginn der Methode parser:didStartElement:namespaceURI:qualifiedName:attributes:
Damit erkennt das Delegate die Zeichenketten in einem XML-Dokument. Da ihre Bedeutung jedoch von den umgebenden Tags abhängt, erfolgt die eigentliche Verarbeitung im Zusammenhang mit den XML-Elementen.
Verarbeitung der XML-Elemente
Zur Verarbeitung der Elemente ist wesentlich mehr Aufwand nötig, da es hier mehrere Anforderungen gibt, die das Delegate beachten muss:
- Für die Tags <activity>, <contact>, <site> und <team> muss es die entsprechenden Core-Data-Entitäten erzeugen und ihnen die Tagattribute zuweisen.
- Es muss die Verbindungen zwischen den Objekten herstellen. Dabei gibt es zwei unterschiedliche Verbindungsarten: Eltern-Kind-Beziehungen (z. B. enthält jedes Team Contact-Elemente) und Referenzen (eine Aktivität verweist über das Attribut team auf sein Team).
- Die Textinhalte einiger Tags (wie beispielsweise <name>, <street>) muss es den richtigen Attributen des entsprechenden Objekts zuordnen.
Diese Anforderungen lassen sich über einen Stapel und den Kontext von Core Data relativ elegant lösen. Er dient dabei als Zwischenspeicher, um die Eltern-Kind-Beziehungen herstellen und die Attributwerte zuordnen zu können.
Stapel
Ein Stapel oder Stack ist eine Datenstruktur, die mehrere Objekte aufnehmen kann. Elemente lassen sich nur oben einfügen oder entfernen, und so kann man sich diese Datenstruktur wie einen Tellerstapel vorstellen. Eine detailliertere Beschreibung finden Sie unter http://de.wikipedia.org/wiki/Stapelspeicher.
Das Delegate verwendet für den Stapel eine private Property namens stack und stellt für den Zugriff drei Methoden bereit. Mit push: legen Sie ein neues Element auf den Stapel, und mit top lesen Sie das oberste Element aus, das Sie mit pop wieder aus dem Stapel entfernen können.
- (void)push:(id)inObject {
[self.stack addObject:inObject];
}
- (void)pop {
[self.stack removeLastObject];
}
- (id)top {
return [self.stack lastObject];
}Listing 8.25 Die Zugriffsmethoden für den Stapel
Das Delegate legt während des Parsens jeweils die Core-Data-Entitäten auf den Stapel und leitet die Ereignisse an das oberste Element im Stapel weiter. Dadurch vermeidet es unschöne Fallunterscheidungen, weil so jedes Element selbst entscheiden kann, wie es das Ereignis verarbeitet.
Abbildung 8.10 veranschaulicht die Verwendung des Stapels während der Verarbeitung des XML-Beispiels aus Listing 8.23. Dabei stellt die linke Seite der Abbildung das XML-Dokument strukturell dar, und auf der rechten Seite sehen Sie den Stapel zu verschiedenen Verarbeitungszeitpunkten. Die Pfeile zwischen dem XML und den Stapeln veranschaulichen die Push- und Pop-Operationen auf dem Stapel. Bei der Verarbeitung der öffnenden Tags (activity, contact, site und team) zu einer Core-Data-Entität legt das Delegate jeweils die entsprechende Entität auf den Stapel und entfernt sie beim schließenden Tag wieder. Alle anderen Tags haben keine Auswirkungen auf den Stapel; stattdessen leitet das Delegate das Ereignis an das oberste Element auf dem Stapel weiter.
Dadurch kann beispielsweise die Site-Entität das End-Element-Ereignis für city verarbeiten und so den Textinhalt dieses Tags ihrem Attribut city zuweisen. Bei der Verarbeitung des city-Tags ist ja die Site-Entität das oberste Element auf dem Stapel, wie Sie in Abbildung 8.10 sehen.
Für die Ereignisweiterleitung gibt es das Protokoll SiteScheduleParseable, das die notwendigen Methoden für die Elemente auf dem Stapel deklariert:
@protocol SiteScheduleParseable<NSObject>
@optional
- (void)siteScheduleParser:(SiteScheduleParser *)inParser
didStartElement:(NSString *)inName
withPredecessor:(id)inPredecessor
attributes:(NSDictionary *)inAttributes;
- (void)siteScheduleParser:(SiteScheduleParser *)inParser
didStartElement:(NSString *)inName
attributes:(NSDictionary *)inAttributes;
- (void)siteScheduleParser:(SiteScheduleParser *)inParser
didEndElement:(NSString *)inName;
@end
Listing 8.26 Das Protokoll für die Ereignisweiterleitung
Das Protokoll deklariert zwei Methoden für das Start-Element-Ereignis und eine für das End-Element-Ereignis. Die zwei Startmethoden unterscheiden zwischen Tags für Entitäten und Attribute. Am Beispieldokument aus Listing 8.23 lässt sich dieser Unterschied veranschaulichen: Für das team-Tag legt die Applikation eine neue Team-Entität an, während sie den Textinhalt des Tags name innerhalb von team als Wert an das gleichnamige Attribut der Team-Entität zuweist. Nach dem Anlegen der Entität ruft das Delegate die Protokollmethode siteScheduleParser:didStartElement:withPredecessor:attributes: auf, während es für die Attributzuweisung die Methode siteScheduleParser:didStartElement:attributes: verwendet. Der Predecessor-Parameter in der ersten Methode enthält das Vorgängerobjekt auf dem Stapel. Dadurch ist es möglich, Baumstrukturen aufzubauen.
Es wäre nun naheliegend, diese Methoden in den Klassen der einzelnen Entitätstypen zu implementieren. Allerdings entstünde bei einer Integration in die Implementierungsdateien der Modellklassen eine direkte Abhängigkeit vom Modell zum Controller. Dieses Problem können Sie jedoch umgehen, indem Sie die Methoden über jeweils eine Kategorie in der Controller-Schicht implementieren. Im Beispielprojekt befinden sich diese Implementierungen der Kategorie jeweils in der Datei SiteScheduleParser.m. Die Kategoriedeklarationen sind hingegen nicht notwendig, weswegen wir sie weggelassen haben.
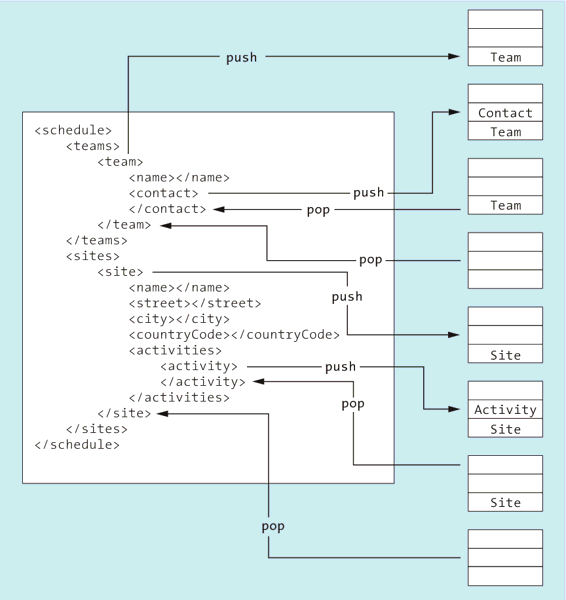
Abbildung 8.10 Verwendung des Stapels während des Parsens
Abhängigkeiten vom Modell zum Controller
Die Implementierung der Protokollmethoden in Kategorien anstatt in den Modellklassen wirkt auf den ersten Blick umständlich und unnötig. Dieses Vorgehen hat dagegen den Vorteil, dass Sie die Modellklassen aus dem Projekt auslagern und in anderen Projekten wiederverwenden können. Das ist mit Controllern häufig nicht möglich, da sie sehr anwendungsspezifisch sind. Durch die Verwendung der Kategorien ist das Delegate eine geschlossene Komponente, die sich dadurch beispielsweise einfach aus dem Projekt entfernen und wieder hinzufügen lässt.
Für die Erstellung und Referenzierung der Objekte braucht die Klasse zwei Hilfsmethoden. Die Methode entityWithName:element:attributes: erzeugt eine neue Core-Data-Entität, fügt sie in den Objektkontext ein und legt sie auf den Stapel. Außerdem ruft sie gegebenenfalls die Methode siteScheduleParser:didStartElement:withPredecessor:attributes: des Objekts auf.
- (id)entityWithName:(NSString *)inEntityName
element:(NSString *)inName
attributes:(NSDictionary *)inAttributes {
id thePredecessor = [self top];
id theEntity = [NSEntityDescription
insertNewObjectForEntityForName:inEntityName
inManagedObjectContext:self.managedObjectContext];
if([theEntity respondsToSelector:
@selector(siteScheduleParser:didStartElement:
withPredecessor:attributes:)]) {
[theEntity siteScheduleParser:self
didStartElement:inName
withPredecessor:thePredecessor
attributes:inAttributes];
}
[self.managedObjectContext insertObject:theEntity];
[self push:theEntity];
return theEntity;
}
Listing 8.27 Anlegen einer neuen Entität
In dieser Methode liest das Objekt die Werte für seine Attribute aus, sofern sie die Tag-Attribute enthalten. Außerdem kann sie gegebenenfalls das Objekt mit seinem Elternobjekt verknüpfen. Ein gutes Beispiel dafür ist die Implementierung in der Kategorie für die Contact-Klasse, die den Parameterwert für predecessor der Property team zuweist. Dieser Parameterwert entspricht dem obersten Element auf dem Stapel, vor dem aktuellen Element. Da das Contact-Element immer in einem team-Element liegt, verweist somit jeder Kontakt auf sein Elternobjekt:
- (void)siteScheduleParser:(SiteScheduleParser *)inParser
didStartElement:(NSString *)inName
withPredecessor:(id)inPredecessor
attributes:(NSDictionary *)inAttributes {
self.team = inPredecessor;
self.phone = inAttributes[@"phone"];
self.isHead = [inAttributes[@"isHead"]
isEqualToString:@"YES"];
}
Listing 8.28 Attributzuweisungen für Kontakte
Die andere Hilfsmethode ist entityNamed:withCode:, die das Core-Data-Objekt sucht, das den angegebenen Code hat. Sie führt diese Suche über eine Suchanfrage durch, die sie zu der Entität mit dem angegebenen Namen erzeugt, und das Prädikat vergleicht dabei das Code-Attribut der Entitäten mit dem entsprechenden Parameterwert.
- (id)entityNamed:(NSString *)inName
withCode:(NSString *)inCode {
NSFetchRequest *theRequest =
[NSFetchRequest fetchRequestWithEntityName:inName];
NSArray *theResult;
NSError *theError = nil;
theRequest.predicate = [NSPredicate
predicateWithFormat:@"code = %@", inCode];
theResult = [self.managedObjectContext
executeFetchRequest:theRequest error:&theError];
if(theError == nil && theResult.count > 0) {
return theResult[0];
}
else {
self.error = theError;
return nil;
}
}
Listing 8.29 Suche nach Elementen zu einem vorgegebenen Code
Nach diesen Vorbereitungen können Sie sich den Delegate-Methoden parser:didStartElement:namespaceURI:qualifiedName:attributes: und parser:didEndElement:namespaceURI:qualifiedName: zuwenden. Bei der Verarbeitung des Start-Element-Ereignisses müssen Sie eine Fallunterscheidung in Abhängigkeit vom Elementnamen machen. Anstatt dafür if-else-Ketten zu verwenden, setzt das Beispielprogramm dynamischen Nachrichtenversand ein: Es erzeugt aus dem Elementnamen einen Methodennamen, indem es an den Namen den Text »WithAttributes:« anhängt und ihn danach in einen Selector umwandelt, um damit die entsprechende Nachricht zu versenden.
Vor dem Nachrichtenversand überprüft die Methode, ob self die Nachricht überhaupt empfangen kann. Falls es die entsprechende Methode nicht gibt, handelt es sich um ein Element mit einem Attributwert. In diesem Fall leitet die Methode die Verarbeitung an das oberste Objekt auf dem Stapel weiter. Listing 8.30 enthält dem Implementierungsblock der Methode parser:didStartElement:namespaceURI:qualifiedName:attributes:.
NSString *theName = [NSString
stringWithFormat:@"%@WithAttributes:", inName];
SEL theSelector = NSSelectorFromString(theName);
[self.text deleteCharactersInRange:
NSMakeRange(0, self.text.length)];
if([self respondsToSelector:theSelector]) {
[self performSelector:theSelector
withObject:inAttributes];
}
else {
id theTop = self.top;
if([theTop respondsToSelector:
@selector(siteScheduleParser:didStartElement:
attributes:)]) {
[theTop siteScheduleParser:self
didStartElement:inName attributes:inAttributes];
}
}
}
Listing 8.30 Verarbeitung des Start-Element-Ereignisses
Xcode warnt Sie in der Zeile mit dem Aufruf von performSelector:withObject: mit der Meldung:
PerformSelector may cause a leak because its selector is unknown.
Die Warnung rührt daher, dass der ARC-Compiler nicht feststellen kann, ob die Methode ein Objekt zurückliefert und ob er gegebenenfalls dieses Objekt freigeben muss. Bei Warnungen sollten Sie in der Regel immer Ihren Code so anpassen, dass diese Warnung nicht mehr auftritt. Das lässt sich hier jedoch leider nur relativ aufwendig realisieren. Zudem erzeugt der Methodenaufruf in diesem Fall auch kein Speicherleck, so dass hier das Ausschalten der Warnung sinnvoll ist.
Mit der Direktive #pragma clang diagnostic können Sie das Warnungsverhalten des Compilers steuern. Die Steuerung der Warnungen erfolgt dabei in Blöcken, die Sie mit #pragma clang diagnostic push einleiten und mit #pragma clang diagnostic pop beenden. Dazwischen können Sie Warnungen über #pragma clang diagnostic ignored "Warnung" aus- beziehungsweise über #pragma clang diagnostic warning "Warnung" einschalten. Nach Beendigung des Blocks gelten dann wieder die Einstellungen wie vor dem Block. Für die betreffende Anweisung müssen Sie die Warnung ?Warc-performSelector-leaks ausschalten. Den entsprechenden Code dazu sehen Sie in Listing 8.31:
#pragma clang diagnostic push
#pragma clang diagnostic ignored
"-Warc-performSelector-leaks"
[self performSelector:theSelector withObject:inAttributes];
#pragma clang diagnostic pop
Listing 8.31 Ausschalten einer Compiler-Warnung
Warnungen in den Wind schlagen
Sie sollten Compiler-Warnungen nur dann ausschalten, wenn Sie sich absolut sicher sind, dass Sie dadurch keinen Programmfehler ignorieren. Achten Sie außerdem darauf, dass Xcode Ihr Programmcode ohne Warnungen kompiliert, und gewöhnen Sie sich auch an, Warnungen immer zu behandeln. Entweder ändern Sie dafür Ihren Code, oder Sie schalten die Warnung im Code aus. Durch das explizite und zeitweise Ausschalten von Warnmeldungen zeigen Sie außerdem anderen Programmierern an, dass hier kein Fehler vorliegt.
Bleibt nun noch zu klären, wie die Methoden aussehen, die der dynamische Nachrichtenversand hier aufruft. Relativ einfach sind die beiden Implementierungen für Aktivitäten und Kontakte, da sie nur das entsprechende Objekt über die Hilfsmethode entityWithName:element:attributes: (siehe Listing 8.27) anlegen müssen:
- (id)activityWithAttributes:(NSDictionary *)inAttributes {
return [self entityWithName:@"Activity"
element:@"activity" attributes:inAttributes];
}
- (id)contactWithAttributes:(NSDictionary *)inAttributes {
return [self entityWithName:@"Contact"
element:@"contact" attributes:inAttributes];
}Listing 8.32 Verarbeitung der Tags »activity« und »contact«
Bei der Verarbeitung der Baustellen und Teams aus unserem Beispiel müssen Sie unterscheiden, ob es dafür jeweils bereits ein Objekt in Core Data gibt. Wenn das Objekt existiert, löschen die Methoden die darin enthaltenen Entitäten, andernfalls legen sie ein neues Objekt an. Die Existenz einer Entität überprüft die Methode anhand des Attributs code, das dabei jeweils als Schlüssel dient.
Schlüsselerlebnisse
Ein Schlüssel (auch Schlüsseleigenschaft genannt) erlaubt es, die Elemente eines Entitätstyps eindeutig zu identifizieren. Beispielsweise ist die Steueridentifikationsnummer ein Schlüssel aller in Deutschland gemeldeten Personen, weil jede Person eine eigene Nummer hat und jede existente Nummer auf genau eine Person verweist. Im Beispielprogramm hat jedes Team und jede Baustelle einen eindeutigen Code.
Schlüssel können sich auch aus mehreren Attributen zusammensetzen. Speichern Sie beispielsweise Telefonnummern in drei getrennten Attributen für Landes- und Ortsvorwahl sowie Durchwahl, dann sind die einzelnen Attribute natürlich keine Schlüssel, da es mehrere Anschlüsse mit der gleichen Durchwahl gibt. Das Tripel aus diesen Attributen ist hingegen ein Schlüssel, da jedes eindeutig auf einen Anschluss verweist.
Listing 8.33 enthält die beiden Methoden zum Aktualisieren von Baustellen und Teams. Wenn diese Methoden das Objekt in Core Data finden, legen sie es auch auf den Stapel, da es ja die enthaltenen Elemente und das schließende Tag verarbeiten muss. Die Methode entityWithName:element:attributes: erzeugt eine neue Entität und legt sie ebenfalls auf den Stapel, wie Sie ja bereits in Listing 8.27 gesehen haben.
- (id)siteWithAttributes:(NSDictionary *)inAttributes {
Site *theSite = [self entityNamed:@"Site"
withCode:[inAttributes valueForKey:@"code"]];
if(theSite == nil) {
theSite = [self entityWithName:@"Site"
element:@"site" attributes:inAttributes];
}
else {
[self push:theSite];
[self.managedObjectContext
deleteObjects:theSite.activities];
}
return theSite;
}
- (id)teamWithAttributes:(NSDictionary *)inAttributes {
Team *theTeam = [self entityNamed:@"Team"
withCode:[inAttributes valueForKey:@"code"]];
if(theTeam == nil) {
theTeam = [self entityWithName:@"Team"
element:@"team" attributes:inAttributes];
}
else {
[self push:theTeam];
[self.managedObjectContext
deleteObjects:theTeam.contacts];
}
return theTeam;
}Listing 8.33 Aktualisierung von Baustellen und Teams
Die Verarbeitung des End-Element-Ereignisses ist relativ einfach; hier prüft die Methode, ob das oberste Stapelelement die entsprechende Nachricht aus dem Protokoll verarbeitet, und sendet sie gegebenenfalls.
- (void)parser:(NSXMLParser *)inParser
didEndElement:(NSString *)inName
namespaceURI:(NSString *)inNamespaceURI
qualifiedName:(NSString *)inQualifiedName {
id theTop = self.top;
if([theTop respondsToSelector:
@selector(siteScheduleParser:didEndElement:)]) {
[theTop siteScheduleParser:self
didEndElement:inName];
}
}
Listing 8.34 Ereignisweiterleitung für das End-Element-Ereignis
Diese Methoden entfernen jeweils das oberste Element vom Stapel, wenn der aktuelle Elementname dem Elementnamen für die Entität entspricht. Beispielsweise entfernt die Implementierung in der Kategorie für die Klasse Team das Element, wenn der Name gleich »team« ist, und bei Elementen mit dem Namen »name« übernimmt sie den aktuellen Text in ihre Property name.
- (void)siteScheduleParser:(SiteScheduleParser *)inParser
didEndElement:(NSString *)inName {
if([inName isEqualToString:@"team"]) {
[inParser pop];
}
else if([inName isEqualToString:@"name"]) {
self.name = inParser.text;
}
}
Listing 8.35 Verarbeitung von schließenden Tags
Fehlerverwaltung
Während der Verarbeitung des XML-Dokuments können natürlich Fehler auftreten. Wenn der Parser im XML-Dokument einen syntaktischen Fehler erkennt, ruft er die Delegate-Methode parser:parseErrorOccurred: auf. Das Delegate des Beispielprojekts speichert diese Fehlermeldung in der Property error ab, so dass das Programm den Fehler nach der Verarbeitung auswerten kann. Der Parser stoppt danach den Verarbeitungsvorgang, und Sie können über seine Propertys lineNumber und columnNumber die Fehlerposition im XML-Dokument bestimmen.
Neben Fehlern im XML-Dokument können dagegen auch noch Fehler während der Verarbeitung auftreten. Wenn beispielsweise das Code-Attribut in einem team-Tag fehlt, ist das entsprechende Attribut auch in der Entität leer, und sie lässt sich nicht abspeichern. In diesem Fall speichert das Delegate den Core-Data-Fehler ebenfalls in der Property error ab.
Start- und Ende der Verarbeitung
Vor der Verarbeitung der XML-Elemente sollte das Delegate den Stapel und den Objektkontext leeren sowie die Fehlermeldung auf nil setzen. Dafür eignet sich das Start-Document-Ereignis:
- (void)parserDidStartDocument:(NSXMLParser *)inParser {
[self.stack removeAllObjects];
[self.managedObjectContext reset];
self.error = nil;
}Listing 8.36 Initialisierung des Delegates beim Starten der Verarbeitung
Entsprechend nutzt das Delegate das End-Document-Ereignis, um die Änderungen des Objektkontextes nach einer fehlerfreien Verarbeitung zu sichern. Trat hingegen bei der Verarbeitung ein Fehler auf, setzt die Methode den Objektkontext zurück, um keine inkonsistenten Daten zu speichern.
- (void)parserDidEndDocument:(NSXMLParser *)inParser {
if(self.error == nil) {
NSError *theError = nil;
[self.managedObjectContext save:&theError];
self.error = theError;
}
else {
[self.managedObjectContext reset];
}
}Listing 8.37 Das Ende der XML-Verarbeitung
Damit haben Sie die wesentlichen Schritte für die SAX-Verarbeitung im Beispielprogramm kennengelernt. Den kompletten Code finden Sie in der Datei SiteScheduleParser.m im Beispielprojekt.
8.3.4DOM und XPath
Wie Sie gesehen haben, benötigt die Verarbeitung selbst eines einfachen XML-Dokuments mit einem SAX-Parser bereits einigen Aufwand, auch wenn die Implementierung insgesamt weniger als 300 Code-Zeilen lang ist. Es gibt mit dem Document Object Model (DOM) noch einen weiteren Ansatz für die XML-Verarbeitung. Ein DOM-Parser erzeugt zu einem XML-Dokument eine Baumstruktur, die dem XML-Dokument entspricht. Sie können sich diesen Baum so wie in Abbildung 8.7 vorstellen, allerdings enthält ein DOM-Baum noch weitere Elemente; beispielsweise stellt er das Dokument, Attribute und Attributwerte ebenfalls als Knoten dar.
DOM
Im Gegensatz zu SAX hat das WWW-Konsortium das Document Object Model entwickelt und standardisiert. Die offizielle Beschreibung dieses Standards können Sie über die Seite http://www.w3.org/DOM einsehen. Eine etwas anschaulichere Darstellung finden Sie allerdings unter http://de.wikipedia.org/wiki/Document_Object_Model.
Derzeit bietet Apple jedoch kein eigenes Framework an, das die XML-Verarbeitung auf Basis von DOM erlaubt. Apple liefert aber mit iOS die Open-Source-Bibliothek libxml2 von Daniel Veillard aus. [Anm.: http://www.xmlsoft.org] Die direkte Verwendung dieser Bibliothek ist nicht sehr komfortabel, da sie nur eine C-API besitzt und Sie deshalb die Daten ständig konvertieren müssen. Glücklicherweise gibt es jedoch einige Open-Source-Projekte, die Wrapper-Bibliotheken für libxml2 implementieren. Eine Wrapper-Bibliothek kapselt die Funktionalität einer anderen Bibliothek, um deren Verwendung zu vereinfachen.
Der wahrscheinlich bekannteste libxml2-Wrapper für Objective-C ist das Open-Source-Projekt TouchXML von Jonathan Wight. [Anm.: https://github.com/TouchCode/TouchXML] Es enthält eigene Klassen für die verschiedenen DOM-Elemente und stellt darüber hinaus einige weitere Werkzeuge für die XML-Verarbeitung zur Verfügung.
TouchXML laden
Der Entwickler Jonathan Wight stellt TouchXML in jeweils einer Version für das automatische und für das manuelle Referenzzählen zur Verfügung. Dabei enthält der Master-Branch die Variante für das manuelle Referenzzählen. Um die ARC-Version zu erhalten, müssen Sie den Branch wechseln, wozu Sie auf der Seite https://github.com/TouchCode/TouchXML so wie in Abbildung 8.11 den Eintrag feature/ARC aus dem Dropdown-Menü auswählen. Über den ZIP-Button oberhalb des Dropdowns können Sie dann die gewünschte Variante herunterladen.
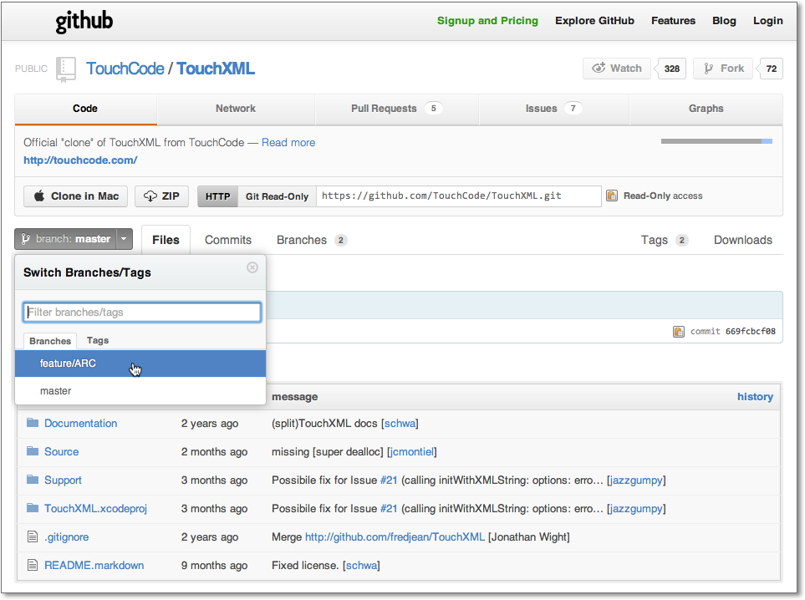
Abbildung 8.11 Auswahl des ARC-Branches von TouchXML
Navigation im DOM-Baum
Die Knoten in einem DOM-Baum haben festgelegte Attribute, mit denen Sie zwischen den Knoten navigieren können. Über parent greifen Sie auf den Elternknoten eines Knotens zu und über children auf dessen Kinder. Außerdem gibt es die Möglichkeit, über previousSibling und nextSibling auf den Vorgänger beziehungsweise den Nachfolger des Knotens in der gleichen Ebene zuzugreifen. Diese beiden Knoten haben den gleichen Elternknoten wie auch der Knoten (siehe Abbildung 8.12).
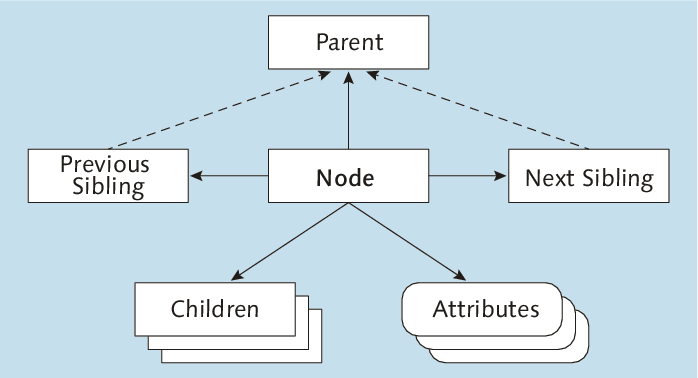
Abbildung 8.12 Navigation im DOM-Baum
Knoten mit dem DOM-Typ Element besitzen ein Attribut attributes, mit dem Sie auf die Attribute des Elements zugreifen können. Auch Attribute sind also Knoten im DOM-Baum. Die Wurzel eines DOM-Baums ist ein spezieller Knoten mit dem DOM-Typ Document, über dessen Attribut rootElement Sie auf das Wurzelelement des Dokuments zugreifen können.
TouchXML bildet die DOM-Typen Document und Element auf die Objective-C-Klassen CXMLDocument beziehungsweise CXMLElement ab, die beide Unterklassen von CXMLNode sind. Diese Oberklasse verwendet TouchXML auch für die Darstellung von Attribut- und Textknoten.
TouchXML einbinden
Wenn Sie das TouchXML-Framework in Ihren Projekten einsetzen möchten, können Sie die Sourcen aus dem Github-Repository laden und zu Ihrem Projekt hinzufügen. Für die Verwendung müssen Sie außerdem an den Compiler und Linker Konfigurationsoptionen übergeben. Dazu fügen Sie am einfachsten die Datei Code/Libraries/TouchXML/TouchXML.xcconfig von der mitgelieferten DVD oder https://github.com/Cocoaneheads/iPhone/tree/Auflage_3/Libraries/TouchXMLTouchXML.xcconfig aus dem Github in Ihr Projekt ein. Bei dieser Datei handelt es sich um eine Xcode-Konfigurationsdatei. Xcode übernimmt die darin enthaltenen Einstellungen, wenn Sie diese Datei wie in Abbildung 8.13 für die Konfigurationen Debug und Release auswählen. In Kapitel 10, »Jahrmarkt der Nützlichkeiten«, erfahren Sie mehr über Xcode-Konfigurationen.
Sie können auch TouchXML als Framework einbinden. Dazu kopieren Sie das Framework unter Code/Frameworks/TouchXML.framework von der beiliegenden DVD oder https://github.com/Cocoaneheads/iPhone/tree/Auflage_3/Frameworks/TouchXML.framework auf Ihre Festplatte und ziehen es von dort auf die Gruppe Frameworks in der Navigationsspalte Ihres Projekts. Achten Sie dabei darauf, die Kopieroption auszuschalten. Außerdem fügen Sie die Xcode-Konfigurationsdatei wie beschrieben zu Ihrem Projekt hinzu.
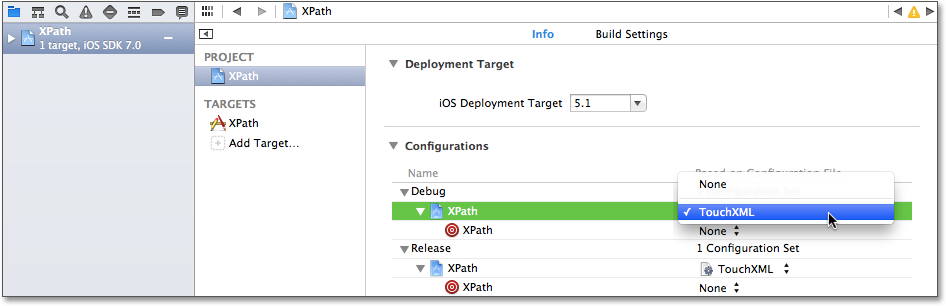
Abbildung 8.13 Auswählen der Konfigurationsdatei
Die Erzeugung eines DOM-Baums mit TouchXML ist relativ einfach; dafür bietet die Klasse CXMLDocument verschiedene Init-Methoden wie beispielsweise initWithData:options:error: oder initWithContentsOfURL:options:error:. Außerdem bieten die Klassen weitere Methoden, die den Zugriff auf die Kindknoten oder die Attribute vereinfachen. Sie können beispielsweise das id-Attribut des ersten user-Elements in Listing 8.13 folgendermaßen auslesen:
CXMLDocument *theDocument = [[CXMLDocument
initWithContentsOfURL:theURL options:0 error:NULL];
CXMLElement *theElement = (CXMLElement *)
[theDocument.rootElement childAtIndex:1];
CXMLNode *theAttribute = [theElement
attributeForName:@"id"];
NSString *theValue = [theAttribute stringValue];
Listing 8.38 Auslesen eines Attributwertes aus einem DOM-Baum
Vielleicht ist Ihnen in Listing 8.38 aufgefallen, dass der Beispielcode nicht das Element mit dem Index 0, sondern das mit dem Index 1 ausliest. Das kommt daher, dass sich im XML-Dokument in Listing 8.13 zwischen dem öffnenden users- und dem user-Tag noch ein Zeilenumbruch und Leerzeichen befinden. DOM bildet auch diese Zeichen in einem Textknoten ab. Wenn die zwei Elemente hingegen direkt aufeinanderfolgen, entfällt auch dieser Textknoten aus dem DOM-Baum. Ein weiteres Problem bei dem Beispiel ist die fehlende Überprüfung bei dem Indexzugriff. Bei einem Dokument ohne user-Tags würde der Elementzugriff wahrscheinlich zu einem Absturz führen.
Knotenzugriff über XPath
Die Verarbeitung von XML-Dokumenten über direkte API-Zugriffe ist also aufwendig und fehleranfällig. Die Anfragespache XML Path Language (XPath) ermöglicht einen einfacheren Zugriff auf die Knoten eines DOM-Baums. Das WWW-Konsortium hat XPath entwickelt und standardisiert. XPath liegt inzwischen in der zweiten Version vor. Zurzeit unterstützt libxml2 und somit auch TouchXML jedoch leider nur die erste Version. [Anm.: http://www.w3.org/TR/xpath]
Der Namensbestandteil Path kommt daher, dass XPath-Ausdrücke Dateisystempfaden sehr ähnlich sehen, und XPath-Pfade können ebenfalls absolut von der Wurzel des Dokuments oder relativ von einem Knoten ausgehen. Wenn Sie mit XPath analog zu Listing 8.38 auf das erste user-Element zugreifen möchten, dann lautet der entsprechende Ausdruck /users/user[1]/@id, und der entsprechende Programmcode sieht so aus:
CXMLDocument *theDocument = [[CXMLDocument
initWithContentsOfURL:theURL options:0 error:NULL];
NSArray *theNodes = [theDocument nodesForXPath:
@"/users/user[1]/@id" error:NULL];
CXMLNode *theAttribute = [theNodes lastObject];
NSString *theValue = [theAttribute stringValue];
Listing 8.39 Auslesen eines Attributwertes über XPath
Der Ausdruck lässt sich am besten über seine Bestandteile verstehen. Da er mit einem Schrägstrich beginnt, handelt es sich um einen absoluten Pfad. Die nächsten Bestandteile users und user selektieren alle user-Elemente, die direkt unterhalb des Wurzelelements users liegen. Der Ausdruck [1] schränkt diese Liste allerdings auf das erste Element ein. XPath verwendet für das erste Element in einer Liste immer den Index 1; der Textknoten ist also hier irrelevant, weil ihn ja schon der Teilausdruck user herausfiltert. Der letzte Pfadteil @id liefert schließlich den id-Attributknoten des Elements.
Auf der DVD finden Sie unter Code/Apps/iOS6/XPath oder im Github-Repository zum Buch im Unterverzeichnis https://github.com/Cocoaneheads/iPhone/tree/Auflage_3/Apps/iOS6/XPath ein iPad-Projekt, mit dem Sie beliebige XPath-Ausdrücke auf einem festen XML-Dokument ausprobieren können. Testen Sie die hier angegebenen XPath-Ausdrücke damit ruhig einmal aus. Sie können das eingebaute XML-Dokument auch gegen ein eigenes austauschen. Spielen Sie mit dem Projekt also ruhig ein bisschen herum; es lohnt sich.
XPath bietet noch eine Fülle weiterer Möglichkeiten, von denen sich hier leider nur die wichtigsten darstellen lassen. Über Pfade können Sie Knoten in dem DOM-Baum auswählen. In Tabelle 8.10 finden Sie die XPath-Ausdrücke, mit denen Sie Pfade konstruieren können.
| Ausdruck | Beschreibung |
|
/ |
|
|
// |
Wählt alle Unterknoten aus, unabhängig von ihrer Tiefe. |
|
. |
Auswahl des aktuellen Knotens |
|
.. |
Selektiert den Elternknoten |
|
Elementname |
Auswahl aller Elemente mit dem Namen Elementname |
|
@Attributname |
Auswahl aller Attribute mit dem Namen Attributname |
|
node() |
Wählt alle Knoten aus. |
|
* |
Selektiert alle Elementknoten. |
|
text() |
Wählt alle Textknoten aus. |
|
@* |
Auswahl aller Attributknoten |
|
Ausdruck1 | Ausdruck2 |
Wählt alle Knoten aus, die auf Ausdruck1 oder Ausdruck2 passen. |
Mit diesen Ausdrücken haben Sie schon recht viele Möglichkeiten. Tabelle 8.10 gibt einige Beispiele.
| Beispiel | Ergebnis |
|
//type |
Liefert alle Elemente des Dokuments mit dem Namen type. |
|
street/text() |
Liefert alle Textknoten, die direkt unterhalb von street-Elementen liegen. |
|
//job | //name |
Selektiert alle job- und name-Elemente des Dokuments. |
|
/users/node() |
Wählt alle Knoten direkt unterhalb des Wurzelelements users aus. Dieser Ausdruck entspricht [theDocument.rootElement children], da er alle Text- und Elementknoten liefert. |
|
users/*/street |
Liefert alle street-Elemente, die Enkel des Unterknotens users sind. |
|
//* |
Liefert alle Elemente des Dokuments. |
|
address/@id |
Liefert alle id-Attributknoten in den address-Elementen. |
|
/users/*/@* |
Wählt alle Attributknoten in den Kindelementen des Wurzelelements aus. |
Durch Achsangaben oder einfach Achsen haben Sie noch weitere Auswahlmöglichkeiten. Dabei schreiben Sie die Achsangabe jeweils durch einen Doppelpunkt getrennt vor die Pfadelemente.
| Achse | Beschreibung |
|
self |
das Element selbst; Alternative zu . |
|
child |
Kindelement; kann auch entfallen. |
|
parent |
Elternelement; Alternative zu .. |
|
ancestor |
alle übergeordneten Elemente |
|
ancestor-or-self |
dieser Knoten und alle übergeordneten Elemente |
|
descendant |
alle enthaltenen Knoten; Alternative zu // |
|
descendant-or-self |
dieser Knoten und alle enthaltenen Knoten |
|
following |
alle nachfolgenden Knoten im XML-Dokument |
|
following-sibling |
alle nachfolgenden Knoten auf der gleichen Ebene wie der Ausgangsknoten, also alle rechten Geschwister |
|
preceeding |
alle vorausgehenden Knoten im XML-Dokument |
|
preceeding-sibling |
alle vorausgehenden Knoten auf der gleichen Ebene wie der Ausgangsknoten, also alle linken Geschwister |
|
attribute |
Attributknoten; Alternative zu @ |
|
namespace |
Namensraumknoten |
Wenn Sie den Ausdruck /users/user[2]/following-sibling::* auf das Beispieldokument aus Listing 8.13 anwenden, erhalten Sie das letzte user-Element als Ergebnis. Wenn Sie hingegen /users/user[2]/following::* verwenden, enthält das Ergebnis außerdem die Teilbäume <name>Lowry</name> und <job>Verwaltungsangestellter </job>, da diese ja auch auf das zweite user-Element folgen.
Über Prädikate können Sie die Auswahl eines XPath-Ausdrucks beschränken. Prädikate stehen immer in eckigen Klammern und folgen auf ein Pfadelement. Mit dem Prädikat wählen Sie Knoten aus, die entweder an einer bestimmten Position stehen oder auf die eine Bedingung zutrifft. Positionsangaben sind ganzzahlige, arithmetische Ausdrücke, wobei last() für die Position des letzten Knotens einer Liste steht und position() die Position des aktuellen Knotens enthält.
Eine Bedingung ist entweder ein einfacher Knotenausdruck oder eine boolesche Bedingung. Ein Knotenausdruck ist erfüllt, wenn das entsprechende Element existiert. Mit booleschen Bedingungen vergleichen Sie hingegen zwei Ausdrücke miteinander. Dabei können Sie sie über die booleschen Operatoren and und or miteinander verknüpfen und über die Funktion [Anm.: Im Gegensatz zu vielen anderen Programmiersprachen müssen Sie hier den Ausdruck in runde Klammern setzen; not @id = 3 ist also ein Fehler.] not negieren.
| Ausdruck | Beschreibung |
|
/users/user[2] /users/user[last()] /users/user[last() – 1] |
Liefert das zweite, letzte beziehungsweise vorletzte user-Element unterhalb von users. |
|
//user[position() > 3] |
Berechnet alle user-Elemente, die jeweils hinter dem dritten user-Element liegen. |
|
//user[@id] |
Liefert alle user-Elemente mit einem id-Attribut. |
|
/root/*/*[@*] |
Enthält die Enkel des Wurzelelementes, die mindestens ein Attribut besitzen. |
|
//user[@id = 3 or @id = 7] |
Selektiert die user-Elemente mit der id 3 oder 7 beziehungsweise mit id-Werten zwischen 3 und 7 (ausschließlich). |
|
//br[not(node())] |
Liefert alle br-Elemente, die keine Unterelemente enthalten. |
|
//*[not(@id)]/.. |
Selektiert alle Elemente mit Kindern ohne id-Attribut. |
|
/root/sub[2]//entry |
Enthält alle entry-Elemente unterhalb des zweiten sub-Elements. |
|
//text()[. = 'Lowry']/ |
Liefert alle Elemente oberhalb des Textes »Lowry«; im Beispieldokument sind das die Elemente users, user und name. |
Außerdem stellt XPath eine Reihe weiterer Möglichkeiten wie beispielsweise Funktionen für Prädikatausdrücke zur Verfügung. Eine vollständige Darstellung von XPath finden Sie im Standard unter http://www.w3.org/TR/xpath oder http://www.w3schools.com/xpath.
Komm, spiel mit mir
Wie Sie gesehen haben, ist die Einbindung von TouchXML und somit die Verwendung von DOM und XPath in eigenen Projekten mit relativ wenig Aufwand verbunden. Sie brauchen nur die Sourcen oder das Framework sowie die Xcode-Konfigurationsdatei einzubinden. Etwas komplizierter ist hingegen gerade für Anfänger die Erstellung des passenden XPath-Ausdrucks. Hierzu können Sie jedoch die besprochene Beispielapplikation XPath nutzen, indem Sie dort Ihre eigenen XML-Dokumente einbinden. Dann können Sie die XPath-Ausdrücke interaktiv ausprobieren und so spielerisch den Umgang mit XPath lernen.
8.3.5Der Tag der Entscheidung
Bei der Anbindung eines bestehenden Dienstes wie beispielsweise YouTube oder Facebook müssen Sie in der Regel ein vorgegebenes Datenformat deserialisieren. Sie brauchen sich also keine Gedanken darüber zu machen, wie Sie Ihre Daten am besten verpacken. Wenn Sie hingegen den Client und Server selbst erstellen, müssen Sie sich für ein Datenformat entscheiden und dessen Struktur festlegen. Mit JSON und XML haben Sie in diesem Kapitel zwei mögliche Datenformate kennengelernt.
Für JSON sprechen zunächst einmal der einfache Aufbau, die einfache Serialisierung und Deserialisierung sowie der sehr geringe Overhead für die Kodierung. Property-Listen sind zwar nicht so kompakt wie vergleichbare JSON-Daten, bieten ansonsten jedoch die gleichen Vorteile und unterstützen zusätzlich Datums- und binäre Datenobjekte. Beide Formate stellen die Daten über Listen, Dictionarys und einfache Datentypen dar, was die Darstellung einfacher Datenstrukturen erleichtert. Dieser Vorteil kann sich dagegen bei komplexeren Daten oder großen Datenmengen leicht in einen Nachteil verwandeln.
Wenn Sie hingegen ein XML-Format verwenden möchten, müssen Sie sich zunächst die Struktur der Dokumente überlegen – also in welchen Elementen und Attributen Sie die Daten ablegen und wie die Elemente untereinander verschachtelt sind. Dabei bildet man die Dokumentenstruktur in der Regel analog zu den betreffenden Klassen ab, so wie beispielsweise im Beispielprojekt SiteSchedule: Jeder der vier Core-Data-Entitätstypen besitzt ein gleichnamiges XML-Element, und die Klassenattribute verwenden ebenfalls gleichnamige Elemente oder Attribute.
Die Entwicklung von applikationsspezifischen XML-Strukturen erfordert zumindest bei sorgfältiger Durchführung zusätzliche Zeit gegenüber JSON oder Property-Listen, was zunächst einmal ein Nachteil des XML-Formats ist. Andererseits lassen sich XML-Formate besser erweitern und verändern, besonders wenn sie eine Rückwärtskompatibilität gewährleisten müssen.
Die Qual der Wahl
Auf die Frage, welches das beste Format ist, gibt es keine allgemeingültige Antwort. Das hängt immer vom Anwendungsfall ab. Viele Webdienste bieten aus diesem Grund mehrere Datenformate an. Grundsätzlich eignen sich JSON und Property-Listen eher für flachere Datenstrukturen, und die Vorteile von XML kommen eher bei komplexeren, tieferen Objektbäumen zum Zuge.
Falls Sie XML als Datenaustauschformat einsetzen, stehen Sie vor der Wahl zwischen SAX und DOM. Die SAX-Verarbeitung ist meistens aufwendiger als der Zugriff auf die DOM-Knoten mittels XPath. Dieser Aufwand lohnt sich in der Regel, wenn Sie aus den XML-Dokumenten den Objektgraphen so wie im Beispielprojekt SiteSchedule rekonstruieren möchten. Der einfache Zugriff auf einzelne Knoten über XPath würde sich hier eher als Nachteil erweisen, und die Rekonstruktion des Objektgraphen wäre in vielen Fällen wahrscheinlich ähnlich aufwendig wie eine Implementierung auf SAX-Basis. Außerdem hätten Sie dabei die Daten unter Umständen doppelt im Hauptspeicher: einmal als DOM-Baum und einmal als Objektgraph.
XPath eignet sich also eher für die punktuelle Auswertung von XML-Dokumenten, besonders wenn Sie einen direkten Zugriff auf einzelne Knoten gut gebrauchen können; in diesem Fall können Sie sich den DOM-Baum als einen Datenspeicher mit wahlfreiem Zugriff vorstellen.
Ihre Meinung
Wie hat Ihnen das Openbook gefallen? Wir freuen uns immer über Ihre Rückmeldung. Schreiben Sie uns gerne Ihr Feedback als E-Mail an kommunikation@rheinwerk-verlag.de.

 Jetzt Buch bestellen
Jetzt Buch bestellen


