

|
|
|
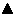 17.0.5 Ausgabedateien bei jedem einzelnen Schritt der Übersetzung erstellen
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Hinweis Am schönsten deckt Folgendes alles ab (Programmiererphobie ;-)): -Wall –Waggregate-return -Wmissing-declarations -Wmissing-prototypes -Wredundant-decls –Wshadow -Wstrict-prototypes -Winline |
Auch der Präprozessor lässt sich mit einer enormen Menge an Optionen beeinflussen. In der Praxis werden allerdings gewöhnlich nur die Optionen -M und -C benötigt (und -D und -U). Mit der Option -M können Sie aus dem Quellcode herauslesen, welche anderen Quelldateien darin enthalten sind. Die so erzeugte Abhängigkeitsliste ist z. B. für MAKE von Bedeutung. Damit lassen sich Makefiles einfacher erstellen. Mit der Option -C sorgen Sie dafür, dass der Präprozessor die Kommentare für nach dem Präprozessorlauf erst einmal nicht entfernt. Diese Option wird dann meistens mit der Angabe von -E verwendet, womit man überprüfen kann, ob der Präprozessor das tut, was man sich vorgestellt hat (eben als Kommentar hingeschrieben hat).
Wichtige Optionen des Compilers, die Sie beide in einem späteren Kapitel noch verwenden werden, sind die Flags zum Erstellen von Daten für das Debuggen oder das Profiling von Anwendungen.
Das Flag -pg wird dafür verwendet, wenn das Programm zum Profiling mit gprof gelinkt werden soll. Die mit diesem erstellten Flag auszuführende Datei mit dem Namen gmon.out enthält Statistiken zur Programmausführung der übersetzten Anwendung. Diese können Sie anschließend mit dem Profiler GPROF auslesen, um noch detailliertere Informationen zur Anwendung zu erhalten.
Verwenden Sie hingegen das Flag -g, wird eine Symboltabelle mit Informationen für das Debuggen mit GDB erstellt. Sofern Sie auf einem System arbeiten, auf dem es GDB nicht gibt, müssen Sie entsprechend der Manual Page eine Symboltabelle für einen anderen Debugger erstellen. So wird mit -gdwarf eine Tabelle für den SVR4-Debugger und mit –gstabs eine für den Debugger DBX unter BSD-Systemen erstellt. Wer in den vollen Debug-Genuss von GDB kommen will, nutzt -ggdb3.
Es steht Ihnen auch eine Reihe von Optionen zur Codeoptimierung zur Verfügung. Natürlich sollte Ihnen damit auch klar sein, dass die Kompilierung des Quellcodes ein wenig länger dauern kann und mehr Speicher in Anspruch nimmt – was allerdings nicht als Nachteil verstanden werden soll, sondern als Hinweis! GCC unterstützt die Kombination -On mit –g (und -gdwarf etc.), jedoch wird der Debugger dem User anscheinend hin und her springen (das hat seine Berechtigung). Debug-Genuss ist mit -O0.
Die Option -O alleine entspricht demselben Aufruf wie die Verwendung der anschließend erklärten -O1-Option. Mit -O0 wird keinerlei Codeoptimierung durchgeführt. Diese Option ist auch die Standardeinstellung des GCC. Dafür versucht der GCC Code zu erstellen, der einfacher zum Debuggen ist. Mit -O1 versucht der Compiler, die Größe des zu erstellenden Codes zu reduzieren und eventuell auch die Ausführgeschwindigkeit der Anwendung zu erhöhen. Mit -O2 wird mittels weiterer Flags versucht, die Option von -O1 nochmals erheblich zu steigern.
Mit der Option -ffast-math wird versucht, eine Floating-Point-Optimierung durchzuführen. Zwar verletzt diese Option den ANSI- als auch den IEEE-Standard, aber die so erzeugten Resultate können erheblich schneller sein – leider auch erheblich fehleranfälliger, daher müssen Sie den Code sorgfältig testen. Die Option -finline_functions fügt bei einfachen Funktionen, anstelle eines Funktionsaufrufs, ein Inlining ein (was auch in C/C++ mit dem Schlüsselwort inline erreicht wird (C erst seit dem C99-Standard)). Der Compiler entscheidet natürlich weiterhin selbst, welche Funktion er dafür verwendet und welche nicht. Meistens erhalten die kleineren Funktionen den Zuschlag. Mit -fno-inline unterbinden Sie das Inlining – auch in den Zeilen, die Sie im Code explizit mit inline gekennzeichnet haben. Mit dem Flag -funroll-loops werden alle Schleifen, die zur Übersetzungszeit eine feste Anzahl von Durchläufen besitzen, in einzelne Codezeilen aufgelöst. Dass bei vielen Schleifendurchläufen die Objektdatei dadurch größer wird, sollte klar sein – was aus der erwünschten Optimierung wieder ein Loch machen kann.
Wenn Sie sich Programmbeispiele, ganze Programme oder gar den Kernel herunterladen, finden Sie immer eine Makefile dabei. Ich denke, jeder hat schon selbst MAKE verwendet und weiß, wozu es gut ist. In diesem Buch wird MAKE nur dazu verwendet, Ihre C-Quellcodes automatisch zu einem ausführbaren Programm zu kompilieren. Nur bedeutet hier, dass MAKE nicht nur für C/C++-Programme verwendet werden kann, sondern es lassen sich damit praktisch beliebige Aktionen ausführen. Dennoch ist das Hauptanwendungsgebiet von MAKE immer noch das Übersetzen von Programmen.
Wenn Sie sich bei einigen Beispielen im Buch immer geärgert haben, dass recht lange und immer wiederkehrende Eingaben für den GCC in der Kommandozeile gemacht werden mussten, kann hier ein einzelner Aufruf von MAKE enorm Arbeit und Nerven ersparen – vor allem je umfangreicher das Projekt wird. Bei der Einführung in MAKE in diesem Buch handelt es sich nur um einen Streifzug zu diesem Werkzeug, die aber für den ersten normalen Hausgebrauch ausreichend sein sollte. Für mehr Details kann immer noch die Dokumentation herangezogen werden – da hier leider (wie so oft im Buch) nur die berühmte Spitze des Eisbergs beschrieben wird.
Um das hier Beschriebene anschließend auch in der Praxis nachzuvollziehen, werden einfachste Codebeispiele verwendet. Folgende Listings sollen dabei erstellt werden:
main.c test1.c test2.c
Alle drei Quelldateien sollen dabei zu einer einzelnen ausführbaren Datei zusammengeführt werden. Am besten, Sie erstellen sich zum Nachvollziehen selbst drei solcher Dateien ohne irgendwelche komplexen Aufgaben. Als Beispiel, falls Ihnen nichts einfällt, können Sie Folgendes verwenden:
/* main.c */
#include <stdio.h>
/* Benötigt häufig die Angabe für den Linker -lm zur Library */
#include <math.h>
extern void test1(void);
extern void test2(void);
int main(void) {
test1();
test2();
printf("%f",sqrt(3.43));
return 0;
}
/* test1.c */
void test1(void) {
printf("Test1\n");
}
/* test2.c */
void test2(void) {
printf("Test2\n");
}
Erstellen Sie hierzu extra einen Ordner (in diesem Fall testmake), und legen Sie die Dateien darin ab.
Gewöhnlich, wenn Sie die drei Quelldateien zu einer ausführbaren Datei gemacht haben, sind Sie vielleicht bisher folgendermaßen vorgegangen:
$ gcc -o mytest main.c test1.c test2.c -lm $ ./mytest Test1 Test2 1.85202
In der Praxis allerdings hat man meistens nur eine Quelldatei modifiziert und möchte auch nur diese eine Datei zu den anderen beiden Modulen hinzulinken. So erstellt man gewöhnlich auch erst drei Objektdateien:
$ gcc -c main.c test1.c test2.c
Sie haben jetzt drei Objektdateien. Wurde z. B. die Datei main.c gerade verändert, so müssen Sie auch nur main.c neu kompilieren:
$ gcc -c main.c
Wollten Sie jetzt eine ausführbare Datei daraus erstellen, dann sind Sie gewöhnlich wie folgt vorgegangen:
$ gcc -o mytest main.o test1.o test2.o -lm
Nein, mir ist bewusst, dass dies kein Problem mehr für Sie darstellt (darstellen sollte), aber worauf ich hinauswill, ist der Overhead, der dabei betrieben wird. Sie müssen sich immer darüber Gedanken machen, wann Sie die eine oder andere Datei übersetzt haben, ob diese nun die aktuellere ist oder welche Bibliothek denn gleich noch hinzugelinkt werden muss oder wie denn gleich noch der Pfad zur Bibliothek lautete.
Zwar gibt es noch die Fraktion, die den kompletten Quellcode immer gleich komplett neu übersetzt – also jedes Mal alles neu erzeugt. Wer schon größere Quelldateien übersetzt hat, weiß, welch unnötiger Irrsinn das ist. Wenn Sie diesen Aufwand bei zehn oder mehr Quelldateien betreiben wollen, werden Sie garantiert länger daran arbeiten, als Sie eigentlich wollen.
Und genau dabei springt MAKE für Sie ein. MAKE hilft Ihnen, den Aufwand der Übersetzung zu minimieren, und reduziert außerdem die Fehleranfälligkeit bei nicht korrekter Übersetzung. Dabei wird Ihnen die Arbeit abgenommen, welche Objektdatei die aktuelle ist oder ob diese überhaupt existiert. Daraufhin werden auch nur die Übersetzungen ausgeführt, die auch wirklich nötig sind. Schließlich muss eine Objektdatei nicht nochmals übersetzt werden, wenn diese bereits existiert.
Das Makefile ist eine Datei, die beschreibt, wie bestimmte Ziele erzeugt werden. Es wird eine Datei aufgelistet, von der die Ziele oder das Ziel abhängig sind. Zusätzlich wird eine Regel vorgegeben, die zum korrekten Übersetzen benötigt wird. Folgende vier Begriffe sollen Ihnen auf den nächsten Seiten in Bezug auf MAKE verständlicher werden: Makefile, Ziel, Abhängigkeit und Regeln.
|
Hinweis Die Beispiele auf den folgenden Seiten wurden mit GNU-MAKE getestet und ausgeführt. |
Damit Sie MAKE verwenden können, benötigen Sie ein Makefile. Das Makefile selbst wird gewöhnlich in jedem Quellverzeichnis verwendet. Darin steht, wie der oder die Quelltexte in diesem Verzeichnis behandelt werden sollen, um ein oder mehrere Programme korrekt zu erstellen. Das Makefile wird gewöhnlich unter dem Namen Makefile gespeichert. MAKE sucht nach seinem Aufruf dann nach dieser Datei.
Als Beispiel soll hier ein einfaches Makefile erstellt werden, das die drei Quelldateien main.c, test1.c und test2.c zu einer ausführbaren Datei macht.
Was Sie zuerst benötigen, ist ein Ziel. Ein Ziel ist meistens eine Datei – was aber nicht sein muss. Es kann sich dabei auch um einen Namen handeln, der das Ziel beschreibt. Das folgende Makefile verwendet zwei Ziele. Mit dem ersten Ziel (testprogramm) wird eine gewöhnlich ausführbare Datei erstellt. Mit dem zweiten Ziel (debugprogramm) hingegen wird eine debug-fähige Version des Programms erzeugt (auf die Details des Debuggens wird noch eingegangen).
# Ein simples Makefile mit zwei Zielen (targets) # Ziel 1: testprogramm: # Datei "mytest" wird erzeugt ... gcc -o mytest main.c test1.c test2.c -lm # ... fertig # Ziel 2: debugprogramm: # Debug-Version wird erstellt gcc -DDEBUG -ggdb3 -o mytest.db main.c test1.c test2.c -lm # ... fertig mit Debug-Version
Speichern Sie dieses Makefile nun ebenfalls im Verzeichnis ab, wo sich die drei Quelldateien befinden. Im Beispiel hier sieht es im Verzeichnis wie folgt aus:
$ ls -Gl insgesamt 16 -rw-r--r-- 1 tot users 301 2004–04–06 14:11 Makefile -rw-r--r-- 1 tot users 101 2004–04–06 07:39 main.c -rw-r--r-- 1 tot users 38 2004–04–06 06:37 test1.c -rw-r--r-- 1 tot users 38 2004–04–06 06:38 test2.c
Jetzt zu einer kurzen Beschreibung der Syntax der folgenden Zeilen:
# Ziel 1: testprogramm: # Datei "mytest" wird erzeugt ... gcc -o mytest main.c test1.c test2.c -lm # ... fertig
Alle Zeilen, die mit dem #-Zeichen beginnen, sind Kommentare. Das Ziel (Target) in diesem Fall ist das Label testprogramm. Enorm von Bedeutung ist das erste Zeichen in der Kommandozeile, was immer ein (˙_)-Zeichen (Tabulator) sein muss. Es genügt also nicht, mit ein paar Leerzeichen hineinzurutschen, sondern es muss ein Tabulatorzeichen sein! Ist hier kein Tabulatorzeichen, wird MAKE mit einer Fehlermeldung Missing Separator abbrechen.
MAKE erzeugt also tatsächlich eine neue Shell, um die Kommandos in der Kommandozeile auszuführen. Würden Sie praktisch das Ziel testprogramm umändern in
testprogramm: ls -l
würde tatsächlich das Inhaltsverzeichnis ausgegeben werden, in dem sich das Makefile befindet. Daran können Sie erkennen, dass sich MAKE nicht nur zur Programmierung eignet.
Jetzt können Sie MAKE aufrufen. Wollen Sie die normale ausführbare Datei (Ziel:testprogramm) erstellen, reicht Folgendes aus:
$ make testprogramm gcc -o mytest main.c test1.c test2.c -lm $ ./mytest
Somit lautet die Syntax für MAKE immer:
make Ziel
Wollen Sie hingegen die Debug-Version der Anwendung von MAKE erzeugen lassen, so geben Sie das Ziel debugprogramm an:
$ make debugprogramm gcc -DDEBUG -ggdb3 -o mytest.db main.c test1.c test2.c -lm
Geben Sie hingegen nur MAKE alleine in der Kommandozeile an, wird das erste im Makefile aufgelistete Ziel verwendet:
$ make gcc -o mytest main.c test1.c test2.c -lm
|
Hinweis Auch wenn hier im Beispiel als Ziel ein anderer Name als der der Anwendung verwendet wurde, ist dies in der Praxis eher unüblich so. Hierbei wird meistens der Name des Programms verwendet. Hier wurde nur ein anderer Name verwendet, damit Sie erkennen können, dass das Ziel und die ausführbare Datei nichts Gemeinsames haben – also das Ziel nichts anderes ist als ein Text-Label. |
Um Ihnen die Abhängigkeit zu erklären, sollten Sie das Makefile zunächst ein wenig umschreiben. Verändern Sie es wie folgt:
# Ein simples Makefile # Ziel mytest mytest: main.o test1.o test2.o # Datei "mytest" wird erzeugt ... gcc -o mytest main.o test1.o test2.o -lm main.o: main.c gcc -c main.c test1.o: test1.c gcc -c test1.c test2.o: test2.c gcc -c test2.c
Führen Sie jetzt, ohne zu verstehen, was hier gemacht wurde, erneut MAKE aus:
$ make gcc -c main.c gcc -c test1.c gcc -c test2.c gcc -o mytest main.o test1.o test2.o -lm $ make make: "mytest" ist bereits aktualisiert.
MAKE erkennt beim zweiten Aufruf, dass hier nichts mehr zu tun ist. Die Daten sind Up –to date. Verändern Sie jetzt etwas an der Quelldatei test2.c, und starten Sie MAKE erneut.
$ make gcc -c test2.c gcc -o mytest main.o test1.o test2.o -lm
Jetzt wird auch wirklich nur die Datei test2.c neu kompiliert, da Sie diese ja eben verändert haben. So viel in der Praxis, aber sicherlich wollen Sie das hier auch verstehen.
In Ihrem ersten Makefile wurden nur die Kommandos verwendet, um das Ziel korrekt zu erzeugen – ohne wirklich den Aufwand dafür zu minimieren. Diesen Aufwand können Sie erst minimieren, wenn Sie eine bedingte Ausführung in das Makefile einbringen. Im ersten Makefile hing das Ziel mytest (bzw. testprogramm) von den Dateien main.c, test1.c und test2.c ab. Aber in Wirklichkeit, wenn man die Dinge genauer betrachtet, hängt das ausführbare Programm mytest schon eher von main.o, test1.o und test2.o ab. Das Ziel mytest hängt somit gar nicht von einer Veränderung von test2.c oder main.c ab, sondern eine Veränderung von test2.c oder main.c betrifft ja nur die Objektdateien test2.o bzw. main.o – was natürlich am Ende mytest doch wieder beeinflusst. Da Ihnen der GCC diese ganze Abhängigkeit der einzelnen Quelldateien hinter dem Linker versteckt, bekommen Sie so gut wie selten etwas davon mit. Aber um effektive Makefiles zu schreiben, müssen Sie sich über diese Abhängigkeit bewusst sein. Daher wurden die Makefiles auch so geschrieben, dass die Kompilierung und das Linken getrennt wurden.
Jetzt zum Makefile:
mytest: main.o test1.o test2.o # Datei "mytest" wird erzeugt ... gcc -o mytest main.o test1.o test2.o -lm
Mit der ersten Zeile geben Sie an, dass das Ziel mytest von den Objektdateien main.o, test1.o und test2.o abhängig ist. In der nächsten Zeile wird, wenn die Abhängigkeit erfüllt ist, die ausführbare Datei daraus gemacht. Ist das Ziel mytest älter als eines der Dateien in der Abhängigkeitsliste, dann wird eine neue ausführbare Datei durch das Linken der Objektdateien erzeugt. Um also für ein Ziel eine Abhängigkeitsliste zu erstellen, muss folgende Syntax verwendet werden:
Ziel : Abhängigkeitsliste
Damit ist Ziel abhängig von allen Dateien in der Liste. Da aber in der eben gezeigten Abhängigkeitsliste nur aus Objektdateien eine Zieldatei erzeugt wird, benötigen Sie noch weitere Kommandos für das Kompilieren der Quelldateien zu Objektdateien. Und auch hier hat wieder jede einzelne Objektdatei eine Abhängigkeitsliste:
main.o: main.c gcc -c main.c test1.o: test1.c gcc -c test1.c test2.o: test2.c gcc -c test2.c
So ist die Objektdatei main.o z. B. abhängig davon, ob der Quelltext main.c verändert wurde. Die Quelldatei main.c, test1.c oder test2.c wird auch nur dann neu kompiliert und zu einer Objektdatei übersetzt, wenn sich diese verändert hat. Wurde, wie es im Beispiel gezeigt wurde, die Quelldatei test2.c verändert, wird der Compilerlauf auch wirklich nur für test2.c gemacht und anschließend, da ja mytest von der Objektdatei test2.o abhängig ist, eine neue ausführbare Datei daraus erstellt. Natürlich kann es durchaus auch sein, dass main.c von einer anderen Header- oder Quelldatei abhängig ist. Solche Dateien sollten Sie immer auch in Ihr Makefile mit einfügen. Z. B. würde mit
main.o: main.c mytest_header.h gcc -c main.c test1.o: test1.c gcc -c test1.c test2.o: test2.c gcc -c test2.c
angegeben, dass main.o jetzt auch noch von der Quelldatei mytest_header.h abhängig ist. Vergessen Sie, dies anzugeben, wird es passieren, dass eine Veränderung von Daten in der Quelldatei mytest_header.h keine Auswirkung auf das Ziel hat. Verändern Sie doch z. B. die Datei test2.c wie folgt:
#include "mytest.h"
void test2(void) {
printf("Test2: %d\n",TEST);
}
Erstellen Sie jetzt eine Datei namens mytest.h mit folgendem Inhalt:
#define TEST 1
Führen Sie jetzt Ihr altes Makefile aus:
$ make gcc -c test2.c gcc -o mytest main.o test1.o test2.o -lm $ ./mytest Test1 Test2: 1 1.852026
Es scheint alles in bester Ordnung. Ändern Sie jetzt den Wert der symbolischen Konstante TEST in mytest.h von 1 auf 2 um, und führen Sie MAKE erneut aus.
$ make make: "mytest" ist bereits aktualisiert.
Sie sehen, die Veränderung von mytest.h hatte keine Auswirkung. Wenn Sie Ihr Makefile jetzt anpassen:
# Ein simples Makefile # Ziel mytest mytest: main.o test1.o test2.o # Datei "mytest" wird erzeugt ... gcc -o mytest main.o test1.o test2.o -lm # Abhängigkeitsliste main.o: main.c gcc -c main.c test1.o: test1.c gcc -c test1.c test2.o: test2.c mytest.h gcc -c test2.c
Jetzt ist dank der Zeile
test2.o: test2.c mytest.h gcc -c test2.c
alles beim nächsten MAKE-Aufruf wieder in Ordnung. Dies sollte hier nicht unerwähnt bleiben, da neben dem Nichtbeachten eines Tabulatorzeichens am Anfang eines Kommandos das Vergessen einer neu erstellten Quelldatei einer der meist gemachten Fehler mit MAKE ist. Wobei eben gerade der Fehler, eine Quelldatei nicht anzugeben, bei MAKE kein syntaktischer Fehler ist und eventuell nicht gleich entdeckt wird.
Im Beispiel eben konnten Sie erkennen, dass ein Makefile so geschrieben werden kann, dass jedes Ziel von einer Datei abhängig ist, die selbst wiederum ein Ziel ist. Das Beispiel könnte natürlich noch vertieft werden. Außerdem hat es den Anschein, dass MAKE von unten nach oben von der Datei arbeitet – dem ist aber nicht so. Es werden immer als Erstes die Ziele auf den neuesten Stand gebracht, die vom eigentlichen Ziel abhängig sind. Ist ein Ziel nicht mehr aktuell, wird eine neue Datei davon erzeugt. Der Vorgang wird so lange ausgeführt, bis alle Ziele auf dem neuesten Stand sind, die für das (Haupt-)Ziel nötig sind.
Sicherlich haben Sie schon häufiger nach einer Ausführung von MAKE auch make clean verwendet, um das Verzeichnis wieder zu säubern. Hierfür müssen Sie nur ein Ziel mit dem Namen clean angeben und ein entsprechendes Kommando setzen:
# Ziel mytest mytest: main.o test1.o test2.o # Datei "mytest" wird erzeugt ... gcc -o mytest main.o test1.o test2.o -lm # Abhängigkeitsliste main.o: main.c gcc -c main.c test1.o: test1.c gcc -c test1.c test2.o: test2.c mytest.h gcc -c test2.c # ...sauber machen ... clean: rm *.o mytest
Führen Sie jetzt in der Kommandozeile make clean aus, werden alle Objektdateien und die ausführbare Datei wieder gelöscht. Sie können rm zum Löschen genauso verwenden, wie Sie es aus der Shell kennen.
In der Praxis sieht das Makefile natürlich nicht so aus, wie Sie dieses in den Abschnitten bisher erstellt haben. Auch hierfür gibt es wieder eine Menge Abkürzungen, die das Schreiben von Makefiles erheblich vereinfachen können. Ändern Sie das Makefile vom Beispiel zuvor wie folgt ab:
# Ziel mytest mytest: main.o test1.o test2.o # Datei "mytest" wird erzeugt ... gcc -o $@ main.o test1.o test2.o -lm # Abhängigkeitsliste main.o: main.c gcc -c $*.c test1.o: test1.c gcc -c $*.c test2.o: test2.c mytest.h gcc -c $*.c # ...sauber machen ... clean: rm *.o mytest
Auffällig sind hierbei die Zeichen $@ und $*, was einfache Ersetzungsmakros sind. Mit $@ geben Sie z. B. den vollen Zielnamen an. Im Fall von
mytest: main.o test1.o test2.o gcc -o $@ main.o test1.o test2.o -lm
bedeutet dies, dass die Zeichenfolge $@ durch den Zielnamen mytest ersetzt wird. Somit verhält sich $@, als würden Sie
gcc -o mytest main.o test1.o test2.o -lm
eingeben. Das Makro $* steht ebenfalls für den Zielnamen, allerdings ohne die Dateiendung. Im Beispiel
main.o: main.c gcc -c $*.c
wird der Zielname main.o an der Stelle ersetzt, wo sich das Makro $* befindet; aber ohne die Endung .o. Neben den Makros $@ und $* gibt es noch einige weitere nützliche Makros, von denen in der folgenden Tabelle einige aufgelistet sind.
| Makro | Bedeutung |
| $@ | Zielname des zu erstellenden Programms |
| $* | Zielname des zu erstellenden Programms ohne Dateiextension |
| $< | Name der ersten Abhängigkeit der aktuellen Regel |
| $^ | Alle Abhängigkeiten |
| $? | Dateiname aller Abhängigkeiten einer Regel, die neuer sind als das Ziel |
| $(@D) | Verzeichnisname von $@ |
| $(@F) | Reiner Dateiname ohne Pfad für $@ |
| CURDIR | Aktuelles Arbeitsverzeichnis, in dem make gerade aktiv ist |
Neben Makros können Sie aber auch Variablen verwenden. Damit könnten Sie z. B. ein Makefile für ein Programm erstellen, was auf vielen anderen Systemen verwendet werden könnte, auf denen z. B. kein GCC als Compiler verwendet wird. Definiert werden Variablen in einem Makefile mit folgender Syntax:
Variable = Wert
Variable wird anschließend im Makefile bei Auftreten von $(Variable) oder ${Variable} durch den entsprechenden Wert ersetzt. Verwenden Sie z. B. den GCC, können Sie diesen in Ihrem Makefile folgendermaßen verwenden:
CC = gcc mytest: main.o test1.o test2.o $(CC) -o $@ main.o test1.o test2.o -lm main.o: main.c $(CC) -c $*.c test1.o: test1.c $(CC) -c $*.c test2.o: test2.c mytest.h $(CC) -c $*.c clean: rm *.o mytest
Mit CC = gcc parametrisieren Sie die Variable CC mit dem Wert gcc. Somit wird bei jedem Vorkommen im Makefile von $(CC) oder ${CC} die Zeichenkette durch gcc ersetzt. Arbeiten Sie jetzt auf einem UNIX-System, das den Compiler CC verwendet und GCC nicht kennt, können Sie das Makefile dennoch ausführen, indem Sie MAKE folgendermaßen verwenden:
$ make CC=cc cc -c main.c cc -o mytest main.o test1.o test2.o -lm
Aber die Verwendung von Variablen spezifiziert sich nicht nur auf Kommandos – ganz im Gegenteil –, damit ist es Ihnen möglich, besser den Überblick zu behalten, indem Sie nur an einer Stelle z.B, alle abhängigen Objekt- oder Quelldateien eines Ziels angeben. Hierzu das Makefile, um einige Variablen erweitert:
CC = gcc OBJECTS = main.o test1.o test2.o LIBS = -lm CFLAGS = -c mytest: $(OBJECTS) $(CC) -o $@ $(OBJECTS) $(LIBS) main.o: main.c $(CC) $(CFLAGS) $*.c test1.o: test1.c $(CC) $(CFLAGS) $*.c test2.o: test2.c mytest.h $(CC) $(CFLAGS) $*.c clean: rm *.o mytest
|
Hinweis Das Flag -c sollte (in professionellen Makefiles) nicht zu den CFLAGS getan werden, da ${CFLAGS} »ohne -c« öfter verwendbar ist als CFLAGS mit -c. |
Mit der Verwendung von Variablen wird die Verwaltung des Makefiles einfacher. Neue Objektdateien, Compiler-Optionen oder zusätzlich verwendete Bibliotheken müssen nur noch am Anfang hinzugefügt werden. Wollen Sie z. B. beim Kompilieren zusätzlich die Flags -Wall für eine umfangreichere Warnungsausgabe und -O für die Optimierung des Codes verwenden, müssen Sie nur noch die Parameter der Variablen CFLAGS verändern:
CFLAGS = -Wall -c –O
Oder entsprechende Angaben beim Aufruf von MAKE machen:
$ make CFLAGS= -Wall –c -O
Das Makefile kann aber noch weiter vereinfacht werden (aus der Sicht des Laien wahrscheinlich erschwert). Häufig werden einzelne Komponente immer wieder auf dieselbe Art und Weise erstellt. In unserem Beispiel werden main.o, test1.o und test2.o immer gleich kompiliert. Diesen Overhead kann man auch noch mithilfe von impliziten Regeln beseitigen. Diese Regeln werden auf eine Menge von Komponenten angewandt, die durch ein bestimmtes Namensmuster – hier die Dateiendung, auch als Suffix bezeichnet – gegeben sind. So besitzen im Beispiel alle drei Ziele main.o, test1.o und test2.o das Suffix .o (für Objektdateien). Des Weiteren werden all diese Objektdateien mit dem Suffix .o aus Quelldateien (main.c, test1.c und test2.c) mit dem Suffix .c erzeugt. Da Sie in diesem Beispiel dreimal den Fall haben, dass aus einer Quelldatei mit dem Suffix .c eine Objektdatei mit dem Suffix .o erzeugt wird, können Sie dies durch eine implizite Regel folgendermaßen beschreiben:
.c.o: Kommando ...
Die Syntax hierzu lautet:
.suffix1.suffix2: Kommando ...
Damit ist suffix1 das Suffix für die Quelle, und suffix2 ist das Suffix für das Ziel. Somit hätten Sie eine implizite Regel, womit aus einer C-Quelldatei eine (Ziel-)Objektdatei erstellt wird. Hiermit sieht der Teil, in dem Sie als Zieldatei eine Objektdatei angegeben hatten, folgendermaßen aus (komplettes Makefile):
.SUFFIXES: .SUFFIXES: .c .o CC = gcc OBJECTS = main.o test1.o test2.o LIBS = -lm CFLAGS = -c -O mytest: $(OBJECTS) $(CC) -o $@ $(OBJECTS) $(LIBS) .c.o: $(CC) $(CFLAGS) $< clean: rm *.o mytest
Sie sollten sich zuerst noch für die Zeilen
.c.o: $(CC) $(CFLAGS) $<
interessieren. Die erste Zeile kennen Sie ja bereits, und in der zweiten Zeile verwenden Sie bis auf $< nichts, was Sie nicht kennen. Mit $< benutzen Sie ein Makro, das den (Datei-) Namen der ersten Abhängigkeit der aktuellen Regel verwendet. Diese Regel wird dabei jedes Mal angewendet, wenn MAKE ein Ziel sucht, das mit .o endet, und eine Datei mit demselben Namen mit der Endung .c existiert – auch wenn keine extra Regeln für dieses Ziel angegeben wurden.
Sollen die Dateiendungen in einem Makefile auch wirklich verwendet werden, müssen Sie diese erst zu einer Regel erklären. Dies machen Sie mit der Zeile:
.SUFFIXES: .c .o
Damit werden alle Quellen des eingebauten Ziels .SUFFIXES als Dateiendung für implizite Regeln verwendet. Im Beispiel sind dies die Quellen .c und die Ziele .o. Die erste Verwendung von
.SUFFIXES:
löscht eventuell vorhandene Suffixe aus der Liste.
Als effektivere und mächtigere Alternative zu den impliziten Regeln mit den Dateiendungen bietet MAKE so genannte Musterregeln an. Bei einer Musterregel steht das Prozentzeichen im Ziel für eine beliebige Zeichenkette. Um auf das durchgehende Beispiel in diesem Abschnitt wieder zurückzukommen, wo Sie aus C-Quelldateien Objektdateien gemacht haben, sieht dieser Vorgang mit Musterregeln wie folgt aus (komplettes Makefile):
CC = gcc OBJECTS = main.o test1.o test2.o LIBS = -lm CFLAGS = -c -O mytest: $(OBJECTS) $(CC) -o $@ $(OBJECTS) $(LIBS) %.o: %.c $(CC) $(CFLAGS) $< clean: rm *.o mytest
Im Beispiel haben Sie mit
%.o: %.c
ein beliebiges Ziel mit %.o definiert, das abhängig von %.c ist. Das Prozentzeichen steht also für eine beliebige Zeichenkette und ist im Gegensatz zur impliziten Regel nicht von Suffixen bzw. Präfixen abhängig. Würde z. B. nur das Prozentzeichen angegeben, dann würde diese Regel auf alle Ziele passen.
Häufig wird MAKE auch zur Installation der Software verwendet. Hierzu wird ein Ziel mit dem Namen install mit entsprechenden Kommandos gesetzt. So lässt sich das fertige Programm systemweit auf dem Rechner installieren. Meistens wird dafür die Anwendung in Verzeichnisse unterhalb von /usr/bin (oder besser /usr/local) installiert. Gewöhnlich werden hierfür Superuser-Rechte benötigt. Hierzu ein möglicher Vorgang einer solchen Installation:
CC = gcc
OBJECTS = main.o test1.o test2.o
LIBS = -lm
CFLAGS = -O2
PREFIX := /usr
my_mytest: $(OBJECTS)
$(CC) -o $@ $(OBJECTS) $(LIBS)
%.o: %.c
$(CC) -c $(CFLAGS) $<
install: my_mytest
install my_mytest ${PREFIX}/bin/
clean:
rm -f *.o my_mytest
Durch die install-Abhängigkeit mytest stellen Sie außerdem sicher, dass mytest immer aktuell ist.
$ make gcc -c -O main.c gcc -c -O test1.c gcc -c -O test2.c gcc -o mytest main.o test1.o test2.o -lm $ su Password:******** # make install install mytest /usr/local/mytest # exit exit $ make clean rm –f *.o mytest
Natürlich können Sie noch weitere Pseudoziele verwenden. Gewöhnlich werden dabei Ziele wie uninstall, check, depend, all und noch einige mehr verwendet. Wie diese Ziele letztendlich arbeiten, ist Ihre Aufgabe. Ich empfehle Ihnen dafür, sich gelegentlich das eine oder andere Makefile anzusehen, wenn Sie wieder eine Software heruntergeladen haben und diese mittels MAKE zusammenbauen und installieren. Versuchen Sie sich aber nicht an komplexeren Makefiles wie solche, die von automake oder configure als Input genommen oder als Output geschrieben worden sind (Makefile.in, Makefile mit vielen @@).
Wie Sie MAKE aufrufen können, haben Sie jetzt mehrere Male gesehen. MAKE bietet Ihnen aber noch mehr Optionen an, die Sie zusätzlich in der Kommandozeile mit angeben können. Welche dass sind, können Sie mit einem Aufruf von make -help ermitteln.
Das Kapitel MAKE könnte noch endlos weitergeführt und erweitert werden – denn damit ließe sich noch eine Menge mehr anstellen als hier beschrieben. Allerdings sollten Sie mit dem Beschriebenen die Grundlagen beherrschen, so dass Sie nun anhand des Lesens anderer Makefiles diese selbst interpretieren und daraus lernen können. Bei all dem sollte man auch nicht übersehen, dass MAKE nicht nur für die Programmierung eingesetzt werden kann. So können Sie MAKE auch zur Verwaltung größerer Dateiarchive oder Dokumentationen verwenden. Wenn Sie wirklich ein sehr komplexes Makefile betrachten wollen, sollten Sie sich das Makefile bekannter und umfangreicher Software ansehen. Empfehlenswert sind die Makefiles von Mozilla, gefolgt vom Kernel und Apache2. Der Hammer ist natürlich Glibc.
| << zurück |
|
||||||||||||
|
||||||||||||
|
||||||||||||
Copyright © Rheinwerk Verlag GmbH 2006
Für Ihren privaten Gebrauch dürfen Sie die Online-Version natürlich
ausdrucken. Ansonsten unterliegt das Openbook denselben Bestimmungen,
wie die gebundene Ausgabe: Das Werk einschließlich aller seiner Teile ist
urheberrechtlich geschützt.
Alle Rechte vorbehalten einschließlich der
Vervielfältigung, Übersetzung, Mikroverfilmung sowie Einspeicherung und
Verarbeitung in elektronischen Systemen.


 bestellen
bestellen



