


20.2
Failover-Cluster 
Der »klassische« Cluster ist der Failover-Cluster, der natürlich auch in Windows Server 2012 vorhanden ist. Die Failover-Clusterunterstützung ist ein nachzuinstallierendes Feature (Abbildung 20.5).
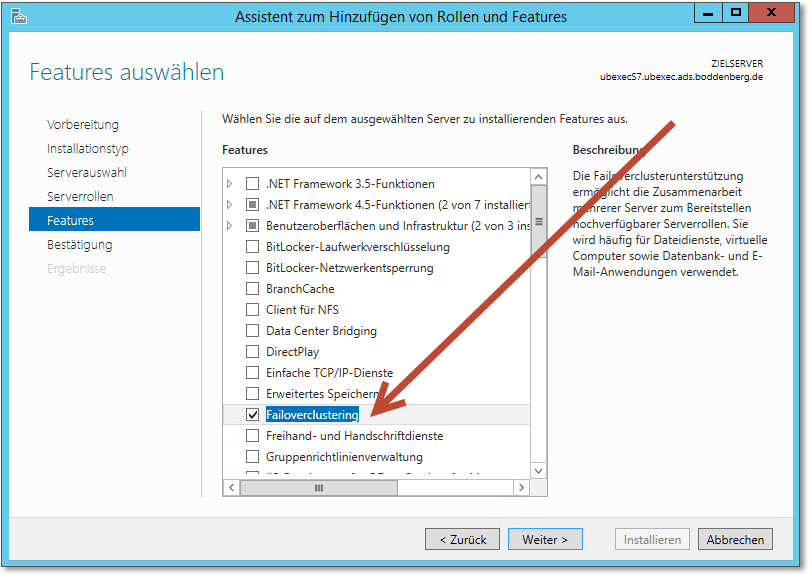
Abbildung 20.5 Das »Failoverclustering« ist ein Feature und wird dementsprechend installiert.
Zwei Hinweise
Der erste wichtige Hinweis dieses Abschnitts ist, dass ein Failover-Clustering auf den Clusterknoten die Enterprise Edition des Betriebssystems voraussetzt.
Der zweite Hinweis dieses Abschnitts ist, dass Sie prüfen sollten, ob ein Failover-Cluster mit gemeinsamem Speicher (Shared Storage) in Ihrem Anwendungsfall wirklich das Optimum ist. Alternative Ansätze sind beispielsweise:
- Der SQL Server 2005/2008/2012 bietet mit der Datenbankspiegelung eine sehr interessante Möglichkeit, um Datenbankserver nebst Festplattenspeicher redundant auszulegen, ohne dass Sie sündhaft teure Hardware beschaffen müssen.
- Exchange 2007/2010/2013 bietet mit der Data Access Group (DAG – vormals Clustered Continuos Replication, CCR) einen Hochverfügbarkeitsansatz, der zwar auf dem Failover-Cluster aufsetzt, aber ohne einen gemeinsamen Speicherbereich aufgebaut werden kann.
Ich möchte mit dieser Anmerkung nicht ausdrücken, dass Failover-Cluster mit gemeinsamem Speicherbereich »irgendwie schlecht« wären. Ich möchte aber sehr wohl darauf hinweisen, dass es durchaus andere Varianten gibt.
Ende 1997, also zur besten NT4-Zeit, veröffentlichte Microsoft einen Clusterdienst, der zur Entwicklungszeit Wolfpack genannt wurde – ein Rudel von Wölfen sorgt also für eine bessere Verfügbarkeit.
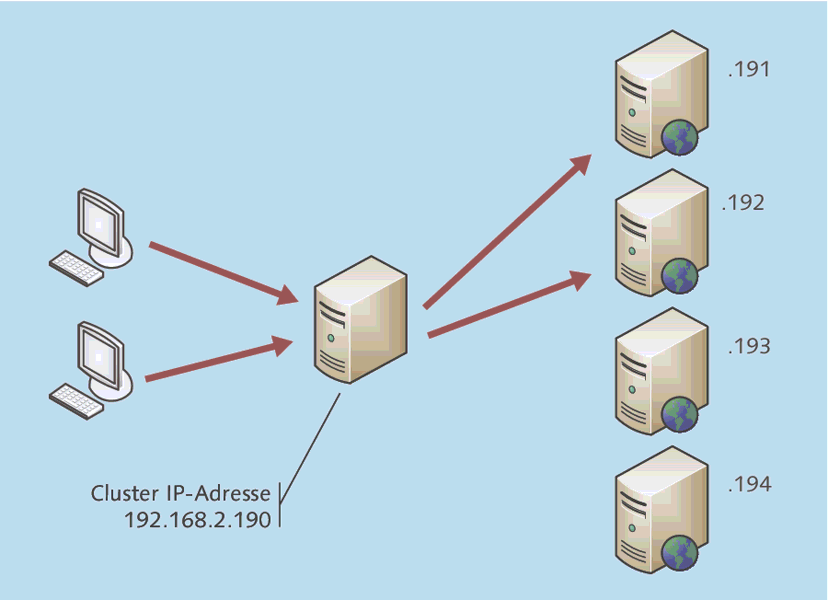
Der Microsoft-Cluster ist recht einfach zu verstehen (Abbildung 20.6):
- Der Cluster besteht aus mindestens zwei Knoten, die über einen gemeinsamen Festplattenbereich
(Shared Storage) verfügen. Dieses Shared-Storage-System kann über Fibre Channel oder
iSCSI angeschlossen sein. Paralleles SCSI wird unter Windows Server 2008 nicht mehr unterstützt.
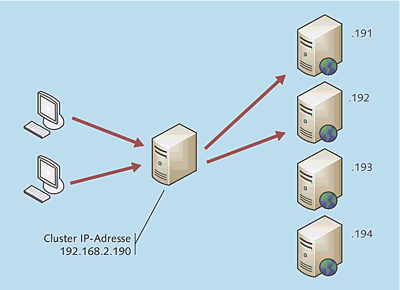
- Die Benutzer greifen, zumindest gedanklich, nicht direkt auf einen der Clusterknoten zu, sondern kommunizieren mit einem »virtuellen Server«, der gewissermaßen vor dem physikalischen Clusterknoten angesiedelt ist. In Abbildung 20.6 ist dies zu sehen: Der Benutzer glaubt, dass er mit alphaClust01. alpha.intra kommuniziert. Da dieses System aber momentan auf alphaCN1 ausgeführt wird, greift der Benutzer in Wahrheit auf diese Maschine zu. Der physikalische Server greift auf den Datenbereich auf dem Shared-Storage-System zu. Wenn alphaCN1 ausfällt oder die Dienste gezielt auf alphaCN2 geschwenkt werden, wird der Client auf diesen physikalischen Server zugreifen, der aber dieselbe Speicherressource und dort dieselben Daten nutzt.
Vorsicht
Ein Szenario, wie es in Abbildung 20.6 gezeigt wird, ist durchaus mit Vorsicht zu genießen: Einerseits wird natürlich der Ausfall eines Serverknotens abgefangen – der eigentlich viel schwerer wiegende Verlust des Speichersystems wird aber andererseits nicht abgedeckt. Nun argumentieren die Hersteller von Speichersystemen zwar, dass die Systeme unglaublich stabil und ausfallsicher arbeiten – es könnte aber trotzdem etwas passieren! Denken Sie an einen Kabelbrand, einen Wasserrohrbruch und dergleichen. Regel Nummer eins beim Entwurf von Hochverfügbarkeitslösungen lautet: »Traue keiner Komponente!«
Abschnitt 3.4 beschäftigt sich recht ausgiebig mit diesem Thema, sodass ich Sie auf diesen Teil des Buchs verweisen möchte.
Wie bereits weiter oben angesprochen wurde, könnten in Ihrem konkreten Fall vielleicht auch Ansätze interessant sein, die nicht auf einem gespiegelten Shared Storage beruhen, sondern die Daten auf Applikationsebene replizieren, also beispielsweise Exchange 2010/2013 DAG oder die Datenbankspiegelung von SQL Server 2005/2008/2012.
Einige weiterführende Anmerkungen:
- Der »virtuelle« Server, auf den die Clients zugreifen, besteht aus mehreren Clusterressourcen, die zu einer Gruppe zusammengefasst werden. Die Gruppe enthält mehrere Ressourcen, wie eine IP-Adresse, einen Rechnernamen, einen Festplattenbereich oder Ressourcen von Applikationsservern wie Exchange oder SQL Server.
- Clusterressourcen können nicht beliebige Dienste oder Programme sein, sondern müssen vom Softwarehersteller speziell auf den Betrieb im Cluster vorbereitet sein. Es ist insbesondere beim Einsatz von Zusatzprodukten zu prüfen, ob diese im Cluster laufen können oder zumindest »Cluster aware« sind. Ersteres bedeutet, dass das Produkt als Clusterressource ausgeführt werden kann. »Cluster aware« heißt, dass die Software zwar keine Clusterressource zur Verfügung stellt, aber stabil auf einem Clusterknoten läuft.
- Im Fehlerfall werden die Clusterressourcen des ausgefallenen Knotens auf dem anderen System gestartet. Dies kann durchaus einige Minuten dauern! Der Cluster sorgt also nicht für »Zero-Downtime«, sondern für eine »Only-a-few-minutes-Downtime«.
20.2.1
Aktiv vs. Passiv und n+1
Grundsätzlich können alle Clusterknoten aktiv sein, also eine Clusterressource ausführen. Es stellt sich allerdings immer die Frage, ob das wirklich die optimale Lösung ist. Abbildung 20.7 zeigt einen Zwei-Knoten-Cluster, bei dem beide Knoten aktiv sind: Fällt ein Clusterknoten aus, wird dessen Ressource auf den anderen Knoten geschwenkt und dort ausgeführt. Das Problem ist, dass dieser Knoten nun die ganze Last allein trägt, bei linearer Verteilung also doppelt so viel leisten muss. Da mehr als 100 % bekanntlich nicht geht, dürfen beide Knoten also jeweils nur zu 50 % ausgelastet sein. Und damit ist der Aktiv/Aktiv-Cluster schon gar nicht mehr so attraktiv.
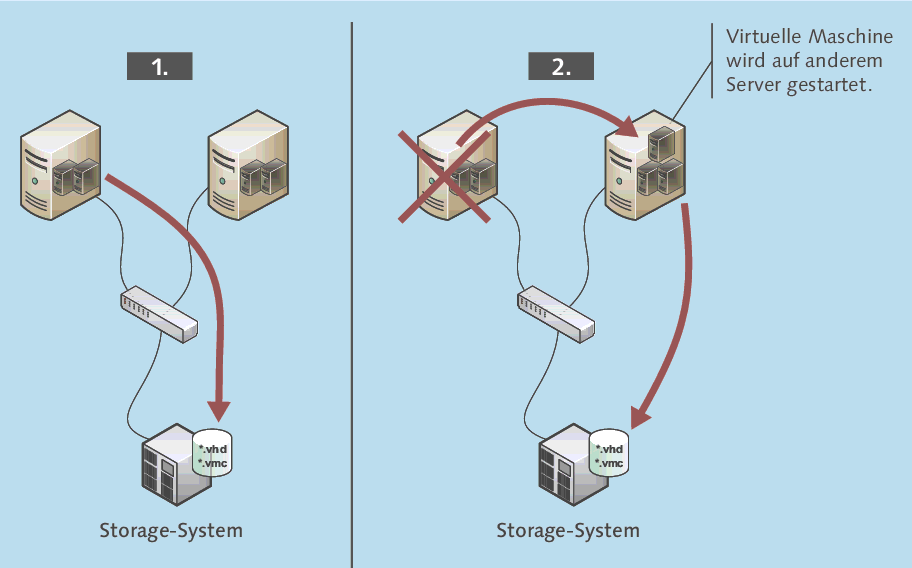
Abbildung 20.7 Bei einem Ausfall in einem Zwei-Knoten-Cluster trägt der verbliebene Knoten die volle Last.
Teilweise wird explizit empfohlen, Zwei-Knoten-Cluster nicht Aktiv/Aktiv, sondern Aktiv/Passiv auszulegen – ein Beispiel dafür ist Exchange Server 2003. Bei Exchange Server 2007 wurden Aktiv/Aktiv-Cluster gar nicht mehr unterstützt, sondern »nur« noch Aktiv/Passiv-Cluster. Die Aktiv/Aktiv-Konfigurationen haben sich in der Praxis schlicht und ergreifend nicht bewährt.
Falls Sie einen Cluster mit noch mehr Knoten benötigen, können Sie bis zu 16 Clusterknoten in einen Cluster einbinden. Bei Clustern, die aus mehr als zwei Knoten bestehen, fährt man grundsätzlich eine n+1-Konfiguration (Abbildung 20.8). Dabei führt einer der Knoten im normalen Betrieb keine Clusterressource aus. Erst im Fehlerfall übernimmt er die Ressource des ausgefallenen Knotens.
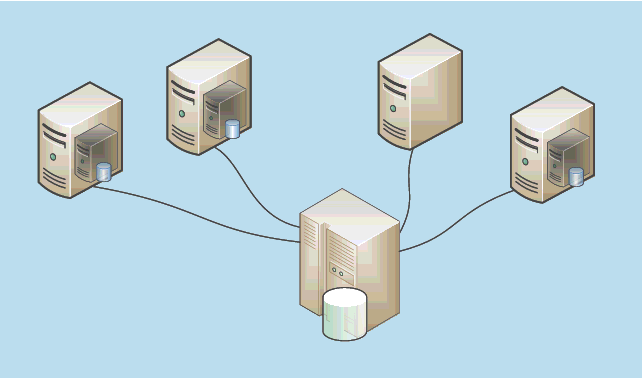
Abbildung 20.8 Bei einem Mehr-Knoten-Cluster bleibt ein Clusterknoten »frei«, um als Ziel für Failover-Vorgänge zu dienen. Man spricht von einer n+1-Konfiguration, in diesem Fall »3+1«.
20.2.2 Installation
Im Gegensatz zum Clusterdienst unter Windows Server 2003 ist als von den Clusterknoten gemeinsam genutzter Speicher kein paralleles SCSI mehr möglich, sondern nur noch Fibre Channel, iSCSI oder SAS (serielles SCSI, Serial Attached SCSI). Für eine Produktionsumgebung hat ohnehin niemand mehr Storage-Systeme über paralleles SCSI angebunden, aber für mit Virtualisierungsprodukten betriebene Testszenarien hat man diese Technologie häufig verwendet.
Wenn Sie zunächst das Clustering mit Windows Server 2012 in einer virtuellen Umgebung testen möchten, empfiehlt sich die Nutzung der iSCSI-Technologie (weil sie preiswerter ist).
iSCSI eignet sich übrigens nicht nur für das Testlabor, auch in der Produktionsumgebung hat sich iSCSI mittlerweile bewährt. Benötigt man höchste Verfügbarkeit und höchste Performance, wird man allerdings nach wie vor zu einem Fibre Channel-SAN tendieren.
Der erste Schritt der Installation besteht darin, dass Sie alle Clusterknoten mit ausreichend Konnektivität ausstatten. Je nachdem, wie Sie den Shared-Storage-Bereich anbinden, benötigen Sie folgende Konfiguration:
- Shared Storage via Fibre Channel:
- 1 × LAN in Richtung Clients (besser redundant auslegen)
- 1 × LAN für Heartbeat
- 1 × FC-HBA für die Anbindung des Storage-Systems (besser redundant auslegen)
- Shared Storage via iSCSI:
- 1 × LAN in Richtung Clients (besser redundant auslegen)
- 1 × LAN für Heartbeat
- 1 × iSCSI-LAN für die Anbindung des Storage-Systems (besser redundant auslegen)
Für iSCSI benötigen Sie also mindestens drei Netzwerkkarten. Das Schaubild aus Abbildung 20.9 verdeutlicht dies.
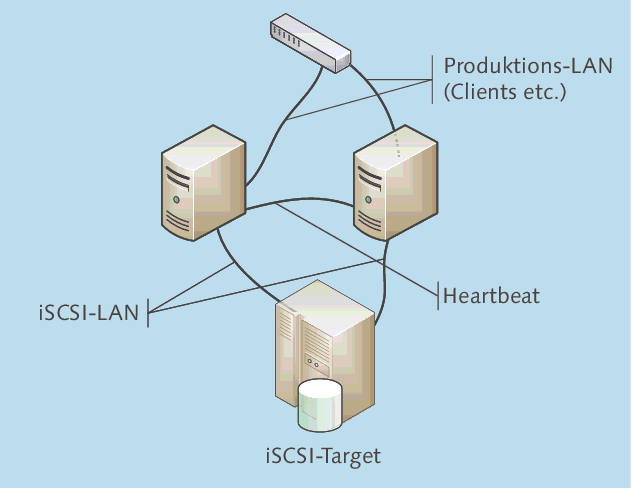
Abbildung 20.9 Ein Clusterknoten in einem iSCSI-Szenario benötigt mindestens drei Netzwerkkarten.
Die Knoten eines Clusters sollten nach Möglichkeit identisch, zumindest aber ähnlich dimensioniert sein.
Ich gehe davon aus, dass viele Leser bisher noch kein iSCSI installiert haben. Daher folgt hier ein kurzer Überblick. Bei iSCSI gibt es zwei Kernkomponenten:
- iSCSI-Target: Ein Target stellt Plattenressourcen zur Verfügung. Windows Server 2012 R2 enthält standardmäßig ein iSCSI-Target, das in diesem Buch auch vorgestellt wird. Diverse Hersteller bieten iSCSI-Targets als Hardwarelösung an. Zu nennen wären hier beispielsweise die Systeme von Network Appliance.
- iSCSI-Initiator: Der Initiator greift auf die vom Target bereitgestellten Ressourcen zu. Ein Initiator kann entweder ein Stück Software oder eine spezielle Netzwerkkarte sein.
Einrichtung des iSCSI-Targets
Erster Schritt ist das Einrichten des iSCSI-Datenträgers. Das Einrichten des eigentlichen Targets habe ich bereits im Dateisystem-Kapitel gezeigt, somit kümmern wir uns hier »nur« noch um den Datenträger. Sie werden eventuell mehrere iSCSI-Datenträger anlegen wollen. Zumindest müssen Sie einen kleinen Datenträger für das Cluster-Quorum anlegen – 1 GB genügt.
Hier die Vorgehensweise:
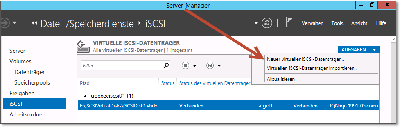
- Öffnen Sie im Server-Manager den Bereich iSCSI und starten Sie das Erstellen eines
Neuen virtuellen iSCSI-Datenträgers (Abbildung 20.10).
- Auf Abbildung 20.11 sehen Sie das Festlegen der Größe des Datenträgers und die Auswahl des Typs.
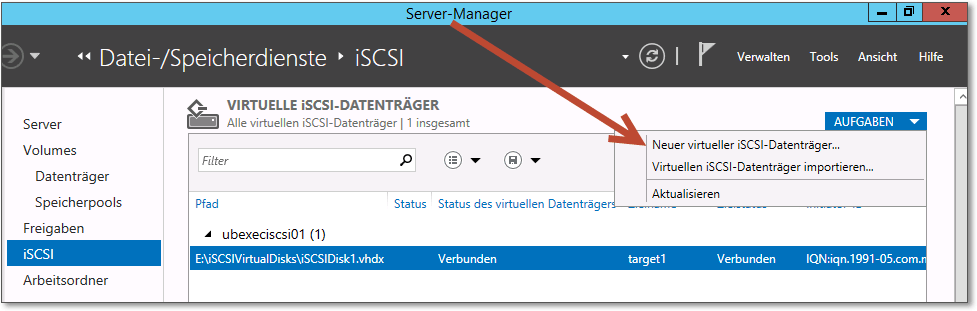
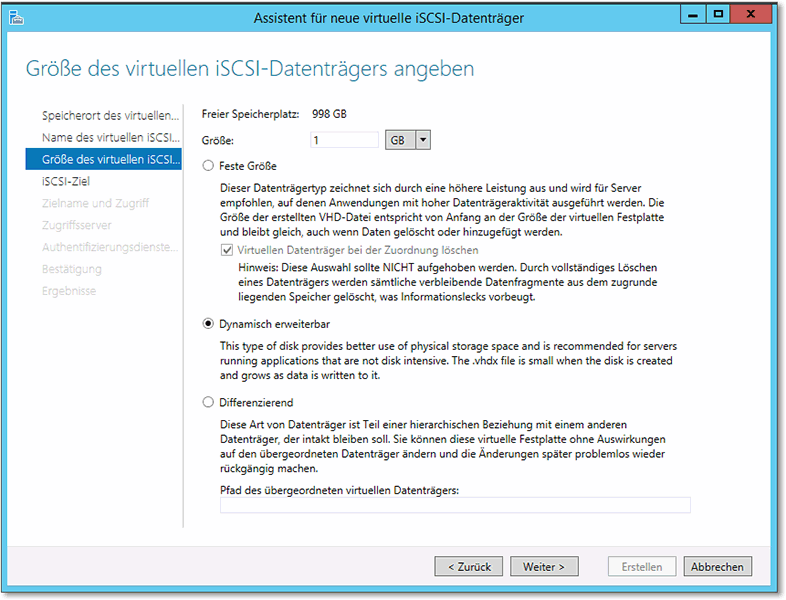
Abbildung 20.11 Für das Quorum reicht ein relativ kleiner Datenträger.
Der iSCSI-Datenträger wird einem Target zugeordnet, das in diesem Beispiel bereits vorhanden ist. Vermutlich werden Sie nochmal die Eigenschaften des iSCSI-Targets kontrollieren und anpassen wollen. Der auf Abbildung 20.12 gezeigte Dialog befindet sich am unteren Ende des iSCSI-Dialogs im Server-Manager.
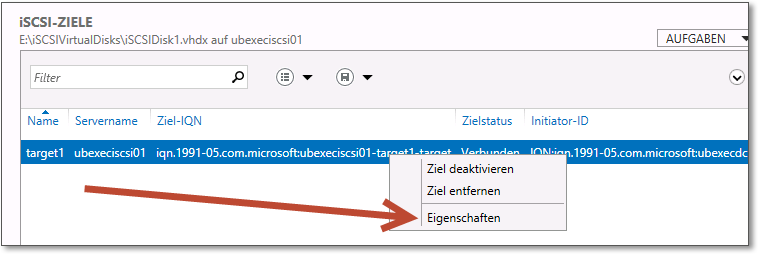
Abbildung 20.12 Das iSCSI-Target wird hier konfiguriert.
Ein allgemein notwendiger Konfigurationsschritt ist das Eintragen der iSCSI-Initiatoren, die auf das Taget zugreifen sollen. Hier müssen also die zukünftigen Cluster-Knoten eingetragen werden (Abbildung 20.13).
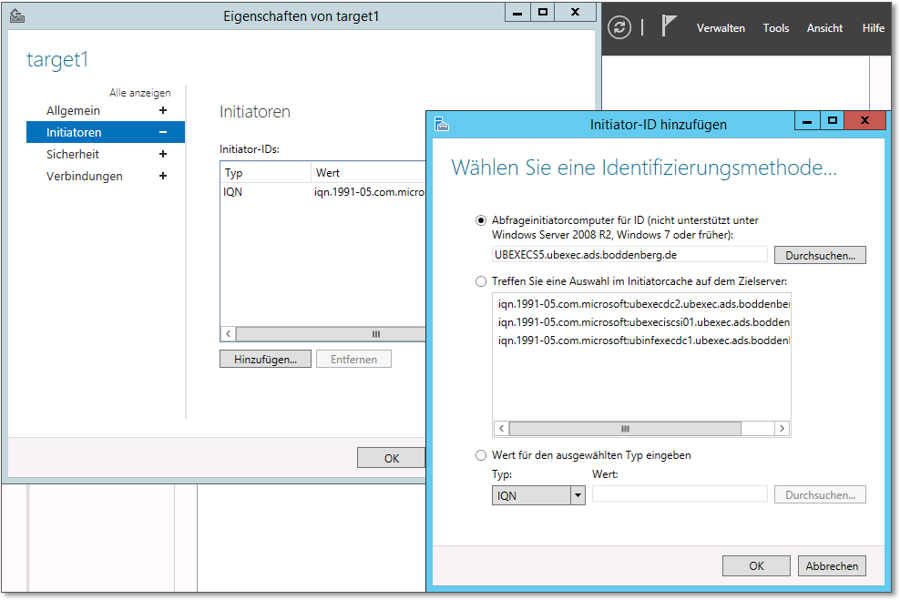
Abbildung 20.13 Die iSCSI-Initiatoren, die zugreifen sollen (die Clusterknoten), müssen eingetragen werden.
Mindestens zwei iSCSI-Bereiche
Erzeugen Sie mindestens zwei iSCSI-Bereiche. Ein Bereich, der nicht größer als 100 MByte zu sein braucht, wird als Quorum verwendet. Vereinfacht gesagt, werden dort »clusterinterne« Daten abgelegt.
Das zweite (dritte, vierte etc.) Device wird für Ihre Daten verwendet.
Konfiguration des iSCSI-Initiators
Nun müssen Sie auf den zukünftigen Clusterknoten noch die Clientkomponente zum Zugriff auf das iSCSI-Target konfigurieren. Eine Installation ist nicht notwendig, da der iSCSI-Initiator seit Windows Server 2008 (also auch in Server 2012 R2) bereits installiert ist, aber nicht ausgeführt wird. Rufen Sie daher den Menüpunkt iSCSI-Initiator auf, und starten Sie auf Nachfrage den Dienst (Abbildung 20.14).
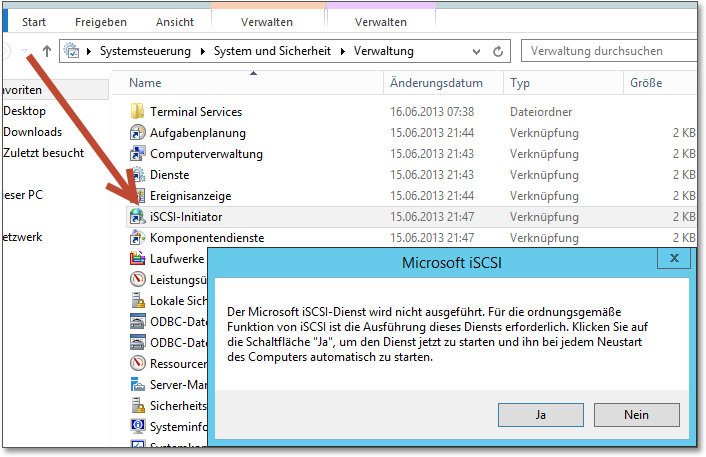
Abbildung 20.14 Der iSCSI-Initiator wird nach dem ersten Start den Dienst beginnen.
Für die Konfiguration des iSCSI-Initiators startet ein Eigenschaften-Dialog mit sechs Registerkarten. Für eine größere iSCSI-Umgebung gibt es recht elegante Konfigurationsmöglichkeiten unter Verwendung eines iSNS-Servers, der in etwa ein DNS-Server für iSCSI ist. Ich möchte an dieser Stelle allerdings nicht in die Tiefen von iSCSI einsteigen, sondern es »nur« zum Laufen bringen:
- Wechseln Sie auf die Registerkarte Ziele, und nutzen Sie die Option Schnell verbinden (Abbildung 20.15). Falls der iSCSI-Server mehrere Netzwerkadressen hat, achten Sie darauf, dass Sie die IP-Adresse des iSCSI-Netzwerksegments eintragen.
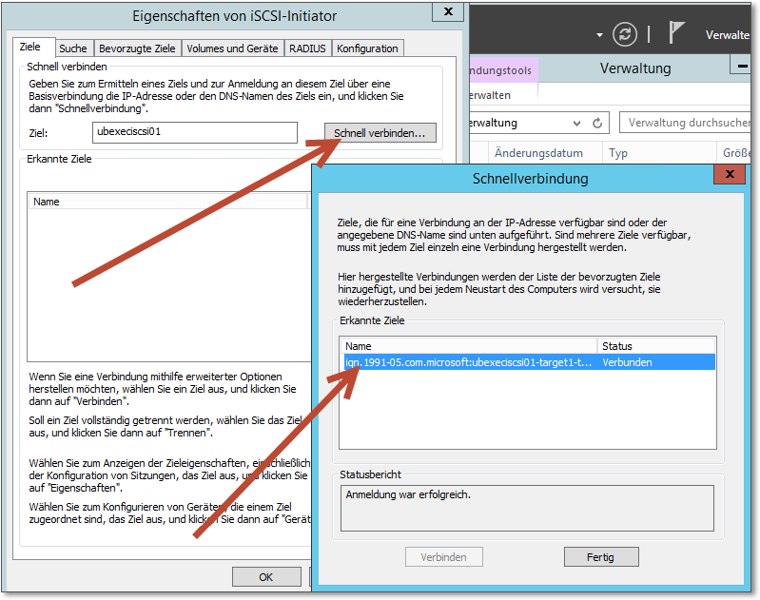
Abbildung 20.15 Das iSCSI-Target wird als Verbindungsziel eingetragen.
Bevor Sie die iSCSI-Konfiguration verlassen, sollten Sie auf die Registerkarte Volumes und Geräte wechseln und dafür sorgen, dass die verwendeten Ressourcen in die Liste eingetragen werden. Ist eine Ressource dort vermerkt, sorgt der iSCSI-Initiator dafür, dass die iSCSI-Ressourcen für die darauf zugreifenden Dienste bzw. Applikationen stets vorhanden sind. Das hört sich ein wenig nebulös an, daher erkläre ich es an einem kleinen Beispiel: Wenn der Server beispielsweise Verzeichnisse des über iSCSI gemounteten Festplattensystems per Dateifreigabe zur Verfügung stellt, wird nach einem Neustart die Freigabe nicht mehr vorhanden sein. Das liegt daran, dass zu dem Zeitpunkt, an dem Dienst startet, der die Freigabe bereitstellt, die Verbindung zum iSCSI-Target noch nicht existiert. In der Folge müssen die Freigaben neu angelegt werden. Das Problem tritt nicht auf, wenn Sie die iSCSI-Ressourcen in dieser Liste eintragen (Abbildung 20.16).
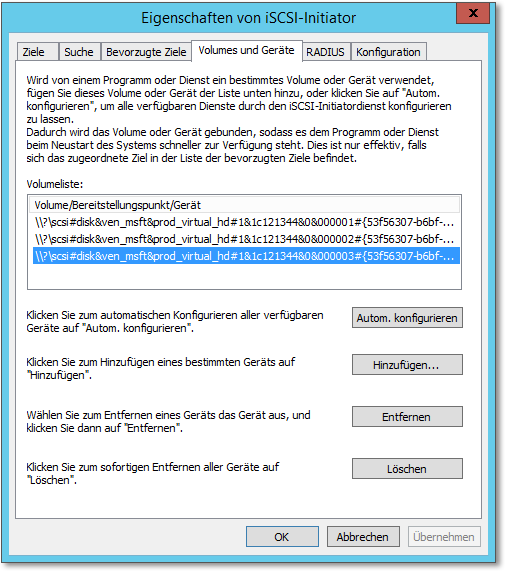
Abbildung 20.16 Wählen Sie »Autom. konfigurieren«, um die Verfügbarkeit der genutzten Geräte sicherzustellen.
Beachten Sie, dass die iSCSI-Ressource auch in der Liste auf der Registerkarte Bevorzugte Ziele vorhanden sein muss. Sie wird dort automatisch eingetragen, aber einmal kontrollieren kann nicht schaden (Abbildung 20.17).
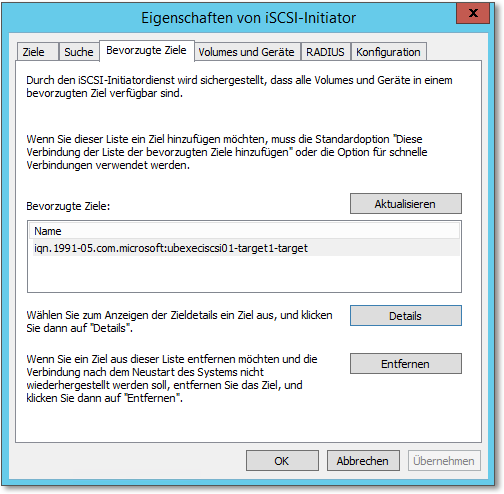
Abbildung 20.17 Das iSCSI-Target muss in den »Bevorzugten Zielen« erscheinen.
In der Datenträgerverwaltung muss sich nun in etwa das Bild aus Abbildung 20.18 ergeben. Die Datenträger müssen noch Online geschaltet werden (im Kontextmenü des Datenträgers), dann können Sie eine Partition anlegen und formatieren. Abbildung 20.19 zeigt, dass die eingebundenen iSCSI-Ressourcen von »normalen« Festplatten nicht zu unterscheiden sind.
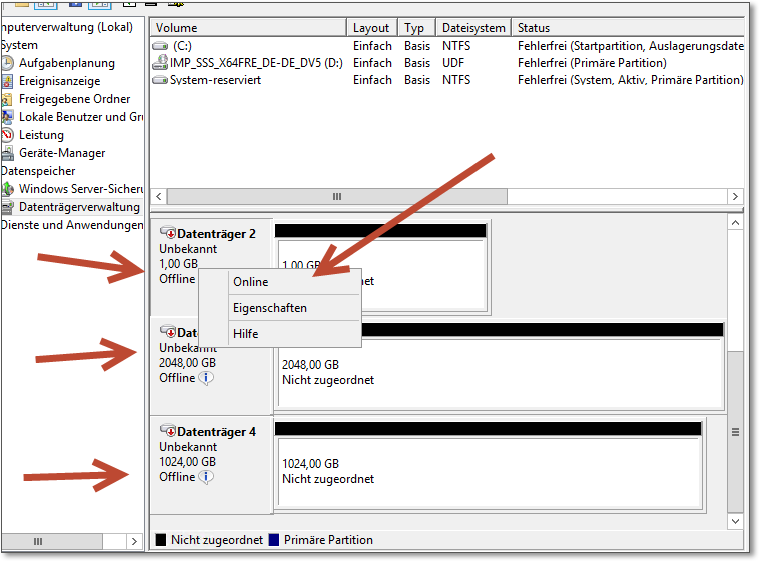
Abbildung 20.18 Die beiden per iSCSI zur Verfügung gestellten Volumes tauchen in der Datenträgerverwaltung auf, müssen aber noch aktiviert, initialisiert und formatiert werden.
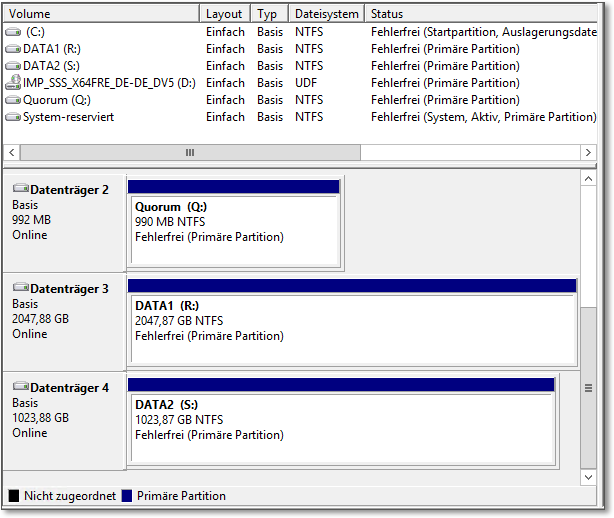
Abbildung 20.19 So muss es aussehen. Und zwar auf beiden Servern!
Keine Laufwerkbuchstaben
Es ist übrigens nicht notwendig, den zukünftigen Clusterfestplatten Laufwerkbuchstaben zuzuweisen. Dies wird ohnehin bei der Clusterinstallation modifiziert.
Hinweis
Die gezeigten Schritte müssen auf allen Clusterknoten durchgeführt werden (natürlich nicht das Partitionieren und Formatieren). Bevor Sie mit der Clusterinstallation fortfahren, müssen alle Clusterknoten auf die Festplattenbereiche zugreifen können.
Sie können übrigens auch im Server-Manager in der Konfiguration des iSCSI-Targets kontrollieren, ob sich alle Server mit dem iSCSI-Target verbunden haben. Es muss sich ein Szenario wie das in Abbildung 20.20 ergeben (s5 und s6 sind die Clusterknoten).
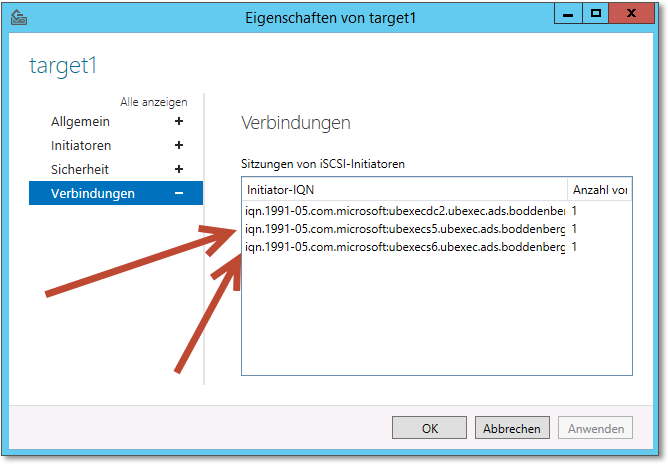
Abbildung 20.20 In der Konfiguration des iSCSI-Targets müssen beide iSCSI-Initiatoren angezeigt werden.
Cluster installieren
Die grundlegenden Arbeiten können Sie mit einem grafischen Werkzeug, dem Failovercluster-Manager, erledigen; das gilt übrigens sowohl für die Einrichtungs- als auch für die Betriebsphase.Die Clusterverwaltung lässt sich übrigens auch auf einem Windows 8-/8.1-PC ausführen; Sie müssen lediglich die Windows Server 2012-Admin-Werkzeuge installieren (RSAT, Download Center). Wie Sie in Abbildung 20.21 sehen können, kann in der Clusterverwaltung viel erläuternder Text aufgerufen werden. Außerdem sind natürlich die wesentlichen Aktionen (Konfiguration überprüfen, Cluster erstellen etc.) aufrufbar.
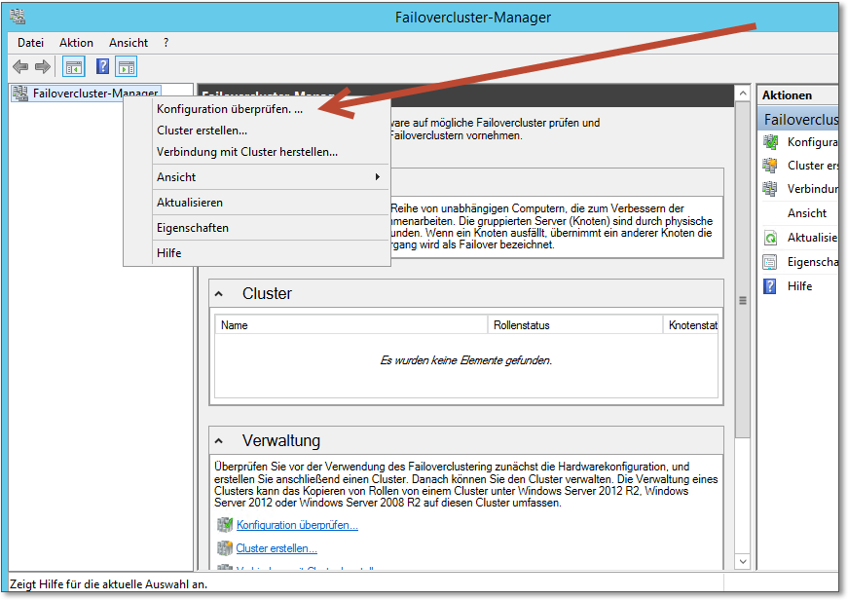
Abbildung 20.21 Die »Failover-Clusterverwaltung« ermöglicht ein komfortables Arbeiten – auch vom Admin-Arbeitsplatz aus.
Konfiguration überprüfen
Eine der Neuerungen beim Failover-Cluster unter Windows Server 2008 waren wesentlich umfangreichere Prüfvorgänge als bei den Vorgängerversionen – in 2012 ist das nochmals erweitert worden. Das ist auch ziemlich gut so, denn meiner Erfahrung nach liegt die Ursache für Clusterprobleme während der Betriebsphase in einer fehlerhaften Grundkonfiguration. Rufen Sie also in der Failover-Clusterverwaltung den Menüpunkt Konfiguration überprüfen auf:
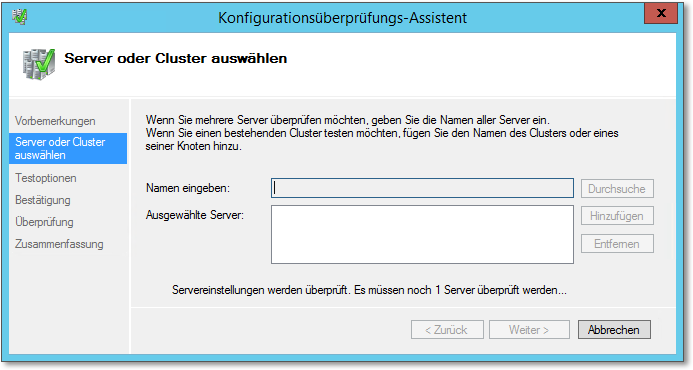
- Zunächst können Sie die zu überprüfenden Server angeben (Abbildung 20.22). Tragen Sie hier alle Server ein, aus denen der Cluster gebildet werden soll.
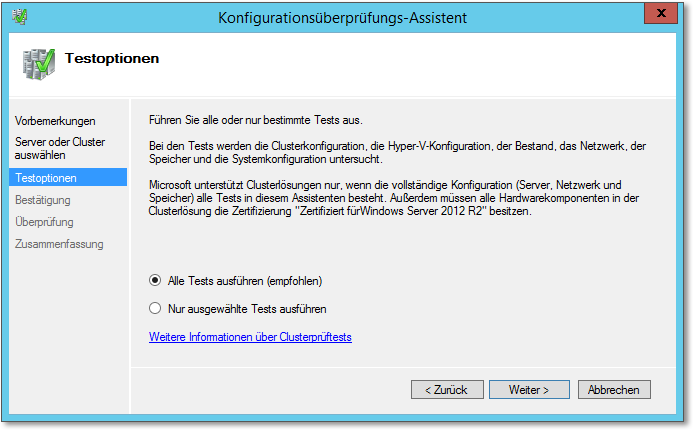
- Auf der dann folgenden Dialogseite können Sie wählen, ob alle Tests durchgeführt werden
sollen oder ob Sie nur einzelne Tests laufen lassen möchten. Der erste Testlauf sollte
alle Tests umfassen. Da die Ausführung einige Minuten dauert, kann später, wenn Sie
einzelne aufgetretene Probleme korrigiert haben, eine selektivere Vorgehensweise empfehlenswert
sein (Abbildung 20.23).
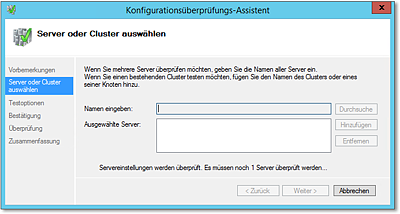
Abbildung 20.22 Wählen Sie zunächst die zukünftigen Clusterknoten zum Test aus.
- Sie können nun den Test starten, der automatisch abläuft. Wie bereits erwähnt, wird
er einige Minuten in Anspruch nehmen.
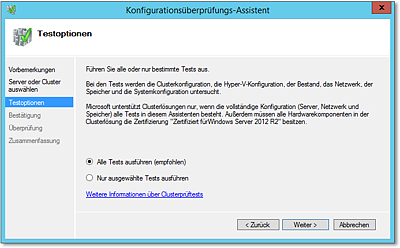
Abbildung 20.23 Sinnvollerweise werden alle Tests ausgeführt.
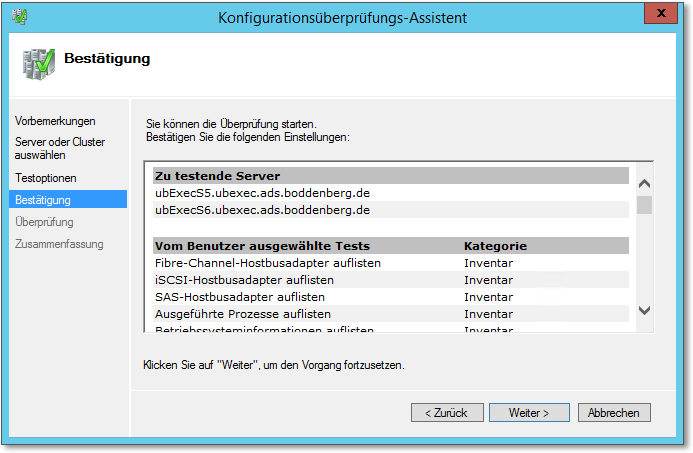
- Der Dialog aus Abbildung 20.24 bringt zwar keine komplizierten Konfigurationsaufgaben mit, ich finde es aber ganz
beeindruckend, zu zeigen, wie viele Tests die Clusterverwaltung bereithält.
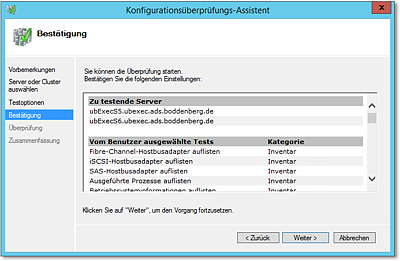
Nach Durchführung des Testlaufs können Sie einen Bericht (HTML-Seite) aufrufen, der sehr detailliert die Ergebnisse auflistet. Sofern Probleme aufgetreten sind, erhalten Sie im Allgemeinen recht konkrete Handlungsanweisungen (Abbildung 20.25).
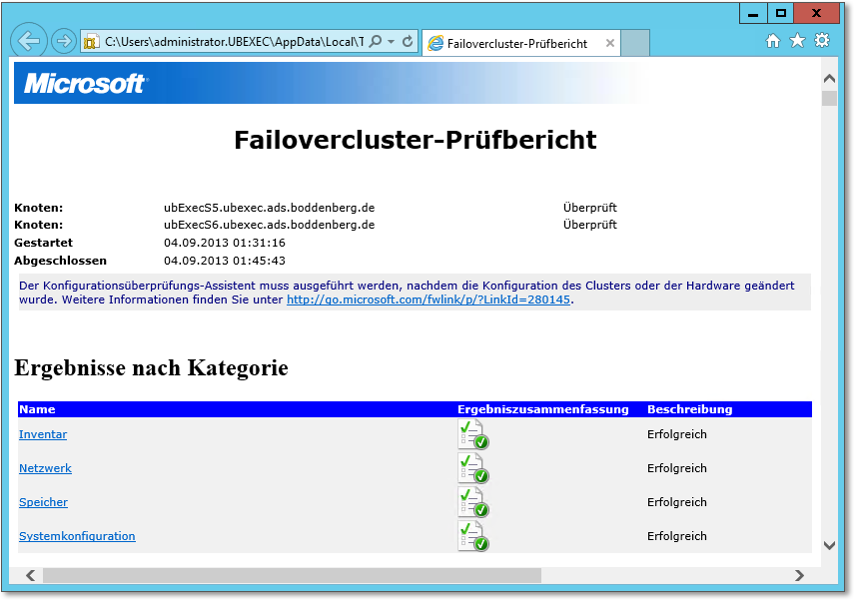
Abbildung 20.25 Der Failovercluster-Prüfbericht
Ich empfehle Ihnen dringend, wirklich so lange zu testen, bis keinerlei Probleme oder Warnungen mehr angezeigt werden. Zwar ist die Clusterinstallation auch möglich, wenn die Konfigurationsprüfung Fehler meldet, allerdings würden daraus zwei Probleme resultieren:
- Eine Konfiguration, die von der Clusterüberprüfung nicht die »grüne Ampel« erhält, wird von Microsoft nicht supportet.
- Wenn die Clusterprüfung Probleme meldet, hat das im Allgemeinen »Hand und Fuß«. Diese Meldungen einfach zu ignorieren, wird mit einer nicht ganz geringen Wahrscheinlichkeit später zu Problemen führen, die dann gegebenenfalls schwer zu diagnostizieren sind.
Cluster erstellen
Nun kommen wir zum eigentlichen Aufsetzen des Clusters. Wählen Sie in der Clusterverwaltung den Menüpunkt Cluster erstellen. Sie werden feststellen, dass Cluster zu erstellen einfacher ist, als Sie es sich vielleicht gedacht haben.
- Zunächst bestimmen Sie, aus welchen Servern der Cluster initial aufgebaut werden soll.
Das ist übrigens keine Entscheidung für die Ewigkeit, Sie können auch zu einem späteren
Zeitpunkt noch weitere Server hinzufügen (Abbildung 20.26).
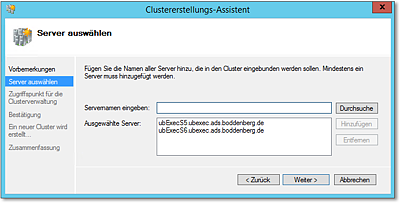
Abbildung 20.26 Wählen Sie die Knoten aus, aus denen der Cluster gebildet werden soll.
- Die eventuell erscheinende nächste Dialogseite ist einigermaßen wichtig. Falls bei dem letzten Validierungstest Warnungen aufgetreten sind, wird der Clustererstellungs-Assistent Sie darauf hinweisen, dass das System nicht von Microsoft supportet werden wird. Sie haben nun die Möglichkeit, den Validierungstest nochmals durchzuführen (vielleicht sind ja die gemeldeten Probleme mittlerweile behoben) oder die Installation trotz der Warnung durchzuführen.
Support
An dieser Stelle sei auf die Bedeutung des Microsoft-Supports hingewiesen. Bekanntermaßen brauchen Sie über wirklich kniffligen Problemen nicht stunden- oder gar tagelang selbst zu brüten, sondern können einen Call bei Microsoft aufmachen. Wenn Sie nicht durch einen wie auch immer gearteten Rahmenvertrag diverse Anrufe frei haben, kosten sie Geld (das staffelt sich u. a. auch nach der Produktfamilie, im Serverumfeld kann man mit ca. 300 € rechnen; Angaben ohne Gewähr!). Für diesen Betrag brauchen Sie nun aber nicht stundenlang selbst nach der Lösung für ein Problem zu suchen.
Ein Call bei Microsoft setzt jedoch voraus, dass die Installation grundsätzlich den »Regeln« entspricht. Wenn Sie wissentlich eine nicht supportete Konfiguration implementieren, verbauen Sie sich die Chance, Ihr konkretes Problem durch Microsoft lösen zu lassen – diesen Weg würde ich mir auf gar keinen Fall verbauen.
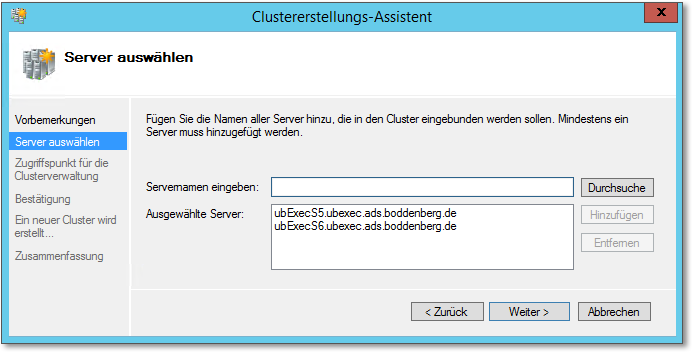
Im nächsten Schritt tragen Sie den Clusternamen und eine zugehörige IP-Adresse ein (Abbildung 20.27). Dies ist die IP-Adresse bzw. der Name, über den der Cluster zu Verwaltungsaufgaben angesprochen wird. Benötigt wird hier eine »neue« Adresse, also keine Adresse eines der Clusterknoten!
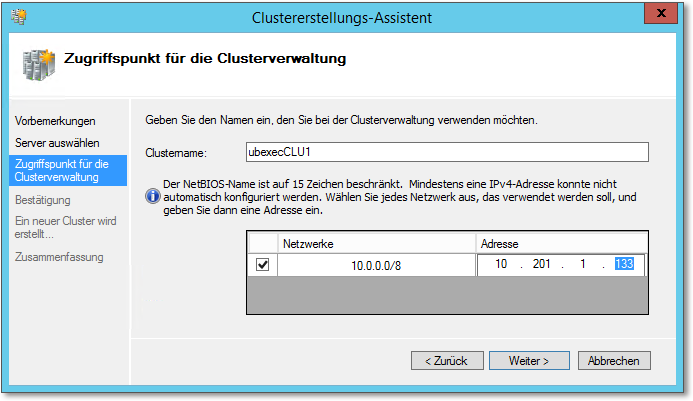
Abbildung 20.27 Für die Clusterverwaltung werden eine IP-Adresse und ein Name benötigt.
Damit haben Sie den Assistenten bereits durchgearbeitet. Nehmen Sie noch eine letzte Überprüfung vor, und dann kann es losgehen (Abbildung 20.28). Die auf dem Screenshot mit dem Pfeil gekennzeichnete Option sollten Sie setzen. Ansonsten müssen Sie beispielsweise auch die Quorum-Disk »per Hand« einbinden. Kann man alles machen, aber wenn der Installations-Assistent das erledigt, ist auch schön.
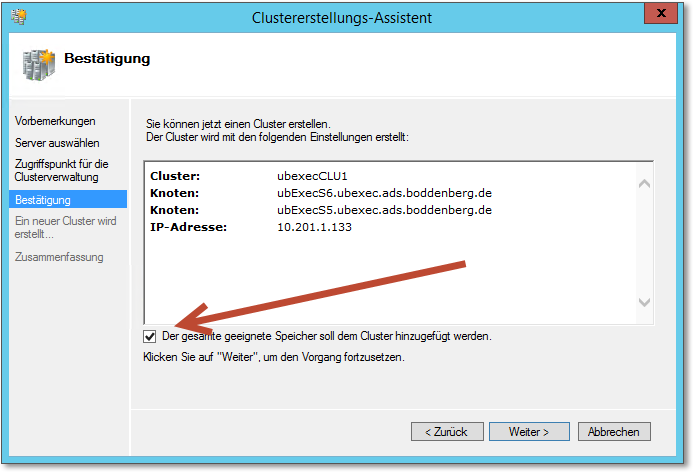
Abbildung 20.28 Ein letzter Check – dann geht es los.
Vielleicht sind Sie erstaunt, dass keine weiteren Parameter abgefragt werden, aber im ersten Schritt geht es »nur« um das Aufsetzen des eigentlichen Clusters. Anwendungen, also Clusterressourcen, werden in einem zweiten Schritt konfiguriert.
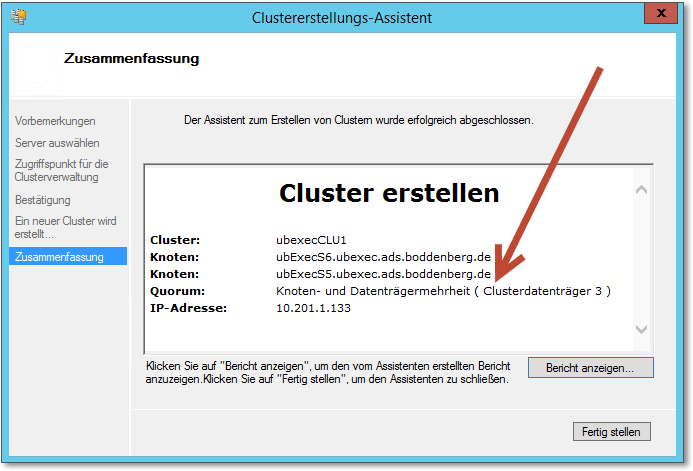
Abbildung 20.29 Das war erfolgreich: Es gibt keine Warnungen, und der Cluster läuft.
Der Assistent wird nun ein paar Minuten lang beschäftigt sein. Wenn Sie den Validierungstest erfolgreich absolviert haben, sollte es aber keine Probleme geben. Abbildung 20.29 zeigt den »Abschlussdialog« einer einwandfrei abgelaufenen Installation. Wenn es Probleme gegeben hat, wird in genau diesem Dialog ein Warnzeichen zu sehen sein. In diesem Fall würde ich übrigens das Problem diagnostizieren (Schaltfläche Bericht anzeigen), den installierten Cluster löschen, das Problem beheben und neu installieren. So können Sie sicher sein, dass Sie wirklich einen »sauberen« Cluster verwenden.
Der Ist-Zustand
Sie werden neugierig sein, wie der Installations-Assistent den Cluster eingerichtet hat. Dies kann in der Failover-Clusterverwaltung problemlos überprüft werden.
Wählen Sie beispielsweise den Knoten Speicher. Dort werden die im Cluster vorhandenen Datenträger angezeigt. Eine besondere Rolle nimmt der Datenträgerzeuge im Quorum ein. Dies ist der Plattenbereich, den der Cluster sozusagen »für sich selbst« benötigt (Abbildung 20.30).
Im Kontextmenü des Knotens Speicher findet sich der Menüpunkt Datenträger hinzufügen, mit dem (Überraschung, Überraschung) dem Cluster weitere Speicherkapazität hinzugefügt werden kann. In Clustern, die auf gemeinsamem Speicherplatz (Shared Storage) basieren, versteht es sich von selbst, dass nur ebendiese gemeinsamen Datenträger hinzugefügt werden können.
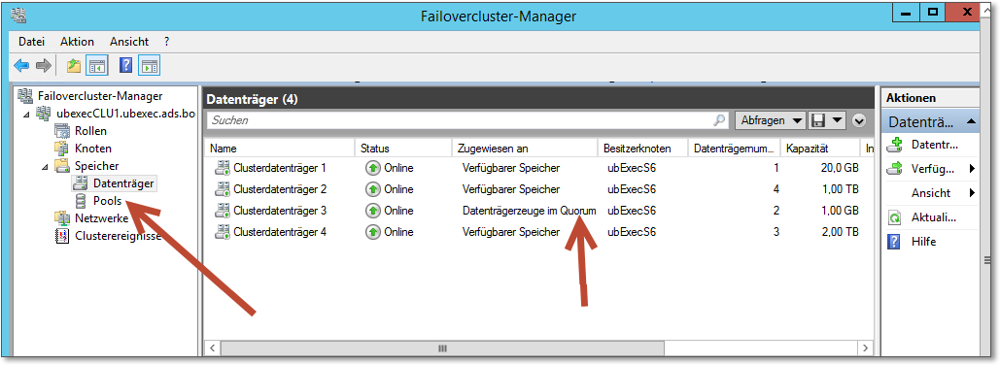
Abbildung 20.30 In der Clusterverwaltung können Sie den im Cluster vorhandenen Speicher einsehen. Beachten Sie besonders den »Datenträgerzeugen«.
Weiterhin interessant ist der Knoten Netzwerke (Abbildung 20.31). Sie können für jedes Netzwerk konfigurieren, ob es vom Cluster verwendet werden darf und ob Clientzugriffe möglich sein sollen. Der Konfigurations-Assistent trifft im Allgemeinen die »richtigen Entscheidungen«, es könnte aber auch sein, dass Sie hier ein wenig nacharbeiten müssen. Rufen Sie dazu den Eigenschaften-Dialog der jeweiligen Netzwerkverbindung auf:
- Die Netzwerkverbindung zum Produktivnetz muss für die Verwendung durch den Cluster zugelassen sein. Weiterhin muss Clientzugriff gestattet sein.
- Für das Heartbeat-Netz muss die Verwendung durch den Cluster aktiviert sein, allerdings muss der Clientzugriff abgeschaltet werden.
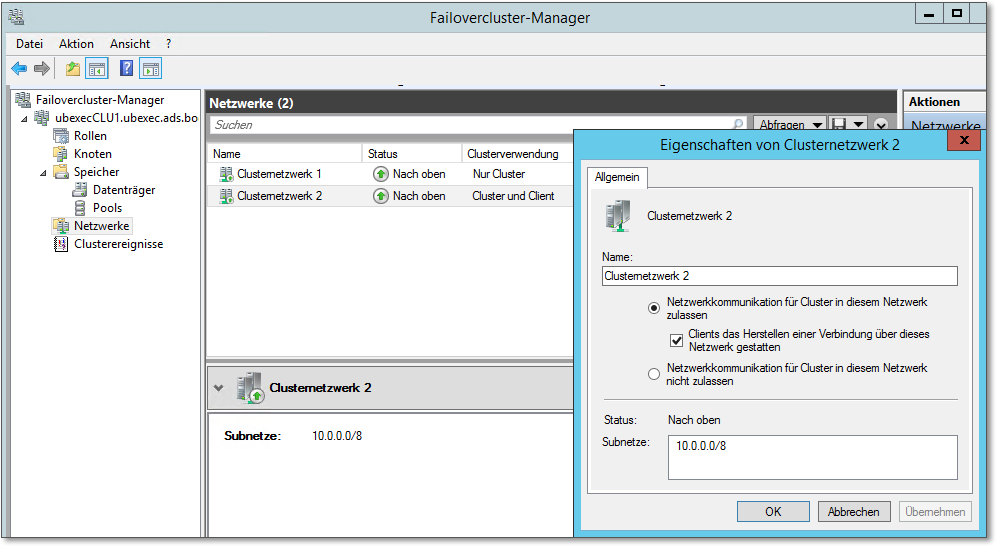
Abbildung 20.31 In der Clusterverwaltung können Sie die im Cluster vorhandenen Netzwerke einsehen und konfigurieren.
20.2.3 Anwendungen hinzufügen
Der Cluster bringt nicht viel, wenn keine Anwendung darauf ausgeführt wird. Die nächste Aufgabe ist also, eine Anwendung oder einen Dienst auf dem Cluster zu konfigurieren. Standardmäßig sind ca. ein Dutzend Anwendungen bzw. Dienste vorhanden, darunter Dateiserver, Druckserver, DHCP-Server und dergleichen mehr. Wenn Sie beispielsweise Exchange Server oder SQL Server auf dieser Maschine installiert haben, werden die entsprechenden Komponenten ebenfalls auf diesem Weg installiert.
Voraussetzung
Die im Cluster auszuführende Rolle muss auf den Clusterknoten, die sie ausführen sollen, installiert sein. Die Fehlermeldungen, die erscheinen, wenn das nicht erledigt wurde, zeige ich Ihnen im weiteren Verlauf.
Als Beispiel in diesem Buch werde ich Ihnen vorführen, wie man einen Dateiserver-Cluster einrichtet. Also:
- In der Failover-Clusterverwaltung rufen Sie im Kontextmenü den Menüpunkt Rolle
konfigurieren auf (Abbildung 20.32).
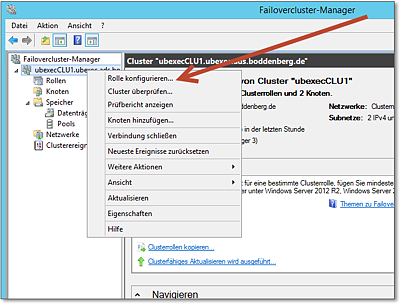
Abbildung 20.32 Hier beginnen Sie mit dem Einrichten eines Diensts oder einer Anwendung.
- Anschließend erscheint der Dialog zur Auswahl der Anwendung, die als Clusterressource installiert werden soll (Abbildung 20.33). Zusätzliche Anwendungen bringen häufig ihre eigenen Installationsroutinen mit, ich zeige Ihnen das später anhand eines SQL-2012-Clusters.
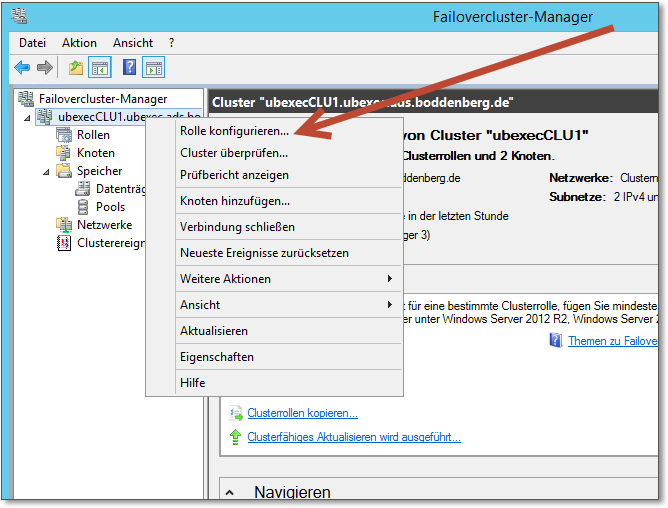
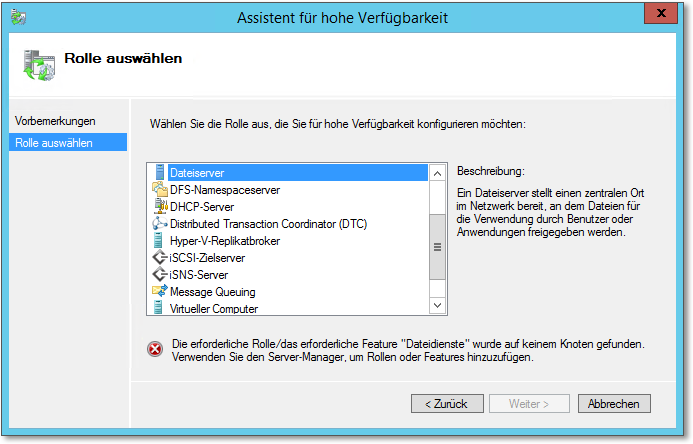
Abbildung 20.33 Eine mögliche Clusteranwendung ist der Dateiserver.
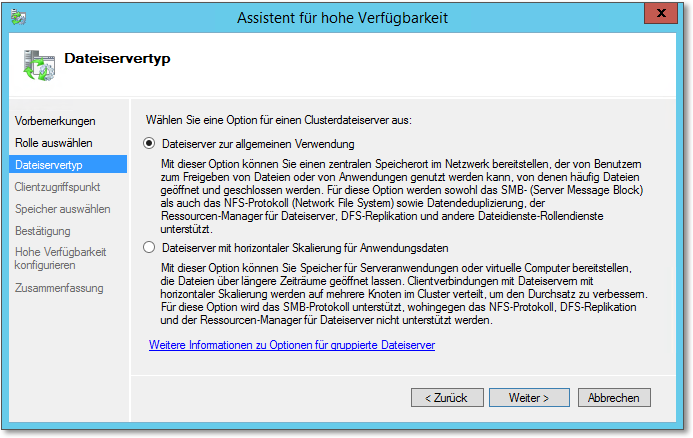
Abbildung 20.34 Ab Server 2012 erscheint diese »Zusatzfrage«. Die Optionen sind ausführlich beschrieben. Für dieses Beispiel wähle ich die erste Option.
Hinweis
In Abbildung 20.33 sehen Sie eine kleine, aber wichtige Fehlermeldung, die besagt, dass die Dateiserverrolle auf keinem Knoten gefunden wurde. Voraussetzung ist, dass die zu clusternden Rollen auf den entsprechenden Knoten vorhanden sind. Die Warnung im Dialog klingt ein wenig so, als müssten sie auf mindestens einem Knoten vorhanden sein – stimmt im Grunde genommen auch. Auf Knoten, auf denen die Rolle nicht installiert ist, kann aber kein Failover stattfinden. Also: Rollen vor Installationsbeginn auf allen Clusterknoten installieren!
Der nächste Punkt ist die Konfiguration des Clientzugriffspunkts (Abbildung 20.35). Den hier angegebenen Namen nebst zugehöriger IP-Adresse verwenden die Clients, um auf die Clusterressource, in diesem Fall den Dateiserver-Cluster, zuzugreifen.
Vorsichtshalber möchte ich Sie darauf hinweisen, dass hier ein nicht existierender Name und eine nicht verwendete IP-Adresse gefordert sind, also keinesfalls die Daten eines bestehenden Clusterknotens.
Übrigens, es wird ein Computerkonto angelegt, und der Name wird im DNS eingetragen.
Im nächsten Dialog wählen Sie die zu verwendenden Speicherbereiche. In diesem Beispiel habe ich nur zwei Datenträger angelegt. Einer davon wird für interne Zwecke benötigt (Datenträgerzeuge im Quorum), der andere kann für die Verwendung mit dem Dateiserver-Cluster ausgewählt werden (Abbildung 20.36). Bei Bedarf können Sie natürlich weitere Datenträger hinzufügen.
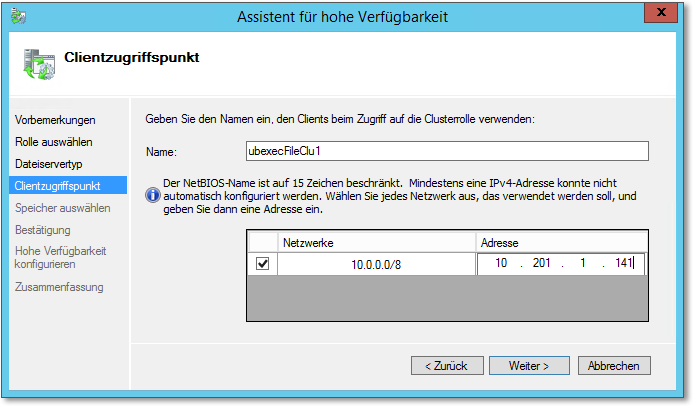
Abbildung 20.35 Wählen Sie einen Namen und eine Netzwerkadresse für den Dateiserver-Cluster.
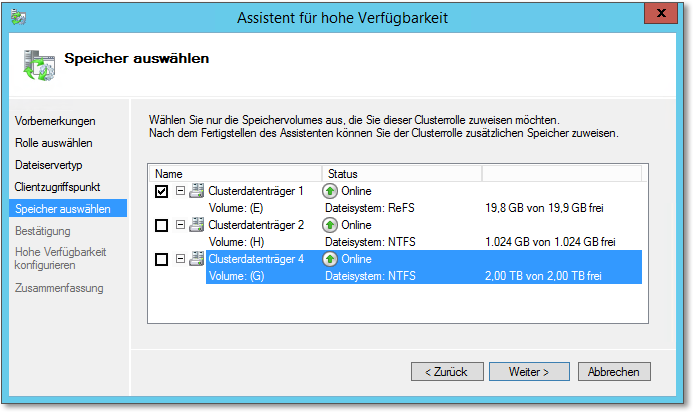
Abbildung 20.36 Legen Sie das Speichervolume fest, das für den Dateiserver-Cluster verwendet werden soll.
Hinweis
Wenn im Cluster Knoten vorhanden sind, auf denen die Rolle nicht installiert ist, erscheint die auf Abbildung 20.37 gezeigte Warnung. Da es sich hier um einen Zwei-Knoten-Cluster handelt, ist die Rolle nicht redundant vorhanden. Das wäre also ein Cluster, der absolut keinerlei Sinn ergibt. Achten Sie darauf, dass das niemals passiert! Wäre sehr peinlich.
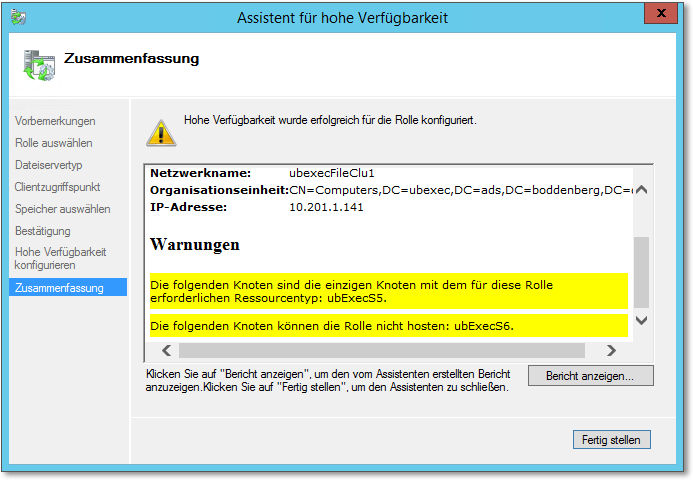
Abbildung 20.37 Warnung, wenn Knoten im Cluster die Rolle nicht installiert haben
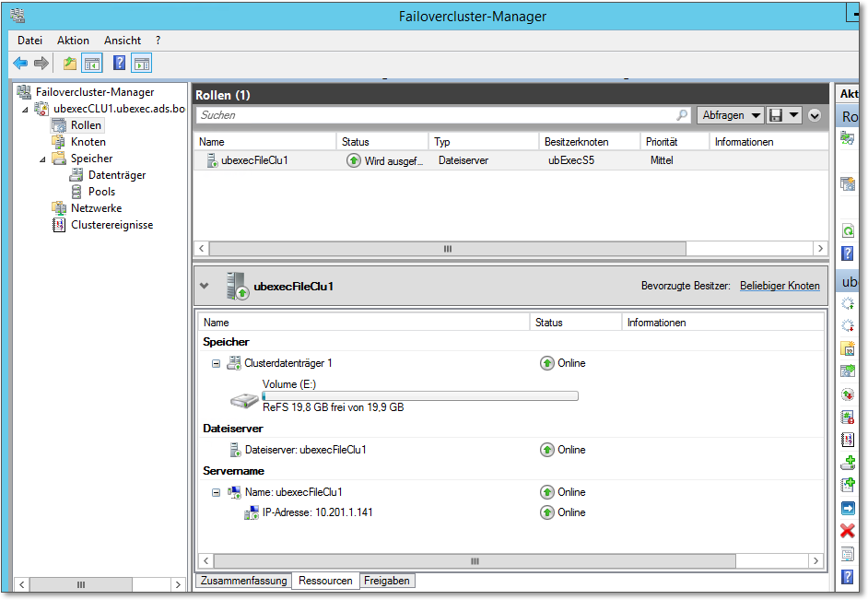
Abbildung 20.38 In diesem Dialog wird der Dateiserver-Cluster konfiguriert. Bisher gibt es nur die administrative Freigabe; immerhin ist alles online geschaltet.
Hat der Assistent seine Arbeit erledigt, können Sie den angelegten Dateiserver-Cluster in Augenschein nehmen (Abbildung 20.38):
- Sie können erkennen, dass der Status des Clusters Online und der aktuelle Besitzer ubExecS5 ist. Wie unschwer zu erraten ist, ist mit Letzterem der Server gemeint, auf dem der Dienst momentan ausgeführt wird.
- Verschiedene Ressourcen haben den Status Online, und zwar der Name, die IP-Adresse und der Clusterdatenträger.
- Momentan gibt es für den Dateiserver-Cluster nur eine Freigabe, nämlich die administrative Freigabe.
Um nun eine weitere Freigabe einzurichten, wählen Sie im Kontextmenü der Dateiserver-Clusteranwendung den Menüpunkt Einen freigegebenen Ordner hinzufügen. Der Assistent, der daraufhin startet, fragt zunächst nach dem freizugebenden Pfad. Dann müssen Sie sich noch durch einige weitere Dialogseiten arbeiten, die aber selbsterklärend sind. Sie sehen, dass die grundlegenden Arbeiten, wie eben das Hinzufügen von Freigaben, in der Clusterverwaltung erledigt werden. Existiert die Freigabe bereits, modifizieren Sie diese in ihrem Eigenschaften-Dialog, den Sie über das Kontextmenü aufrufen (Abbildung 20.39, Abbildung 20.40).
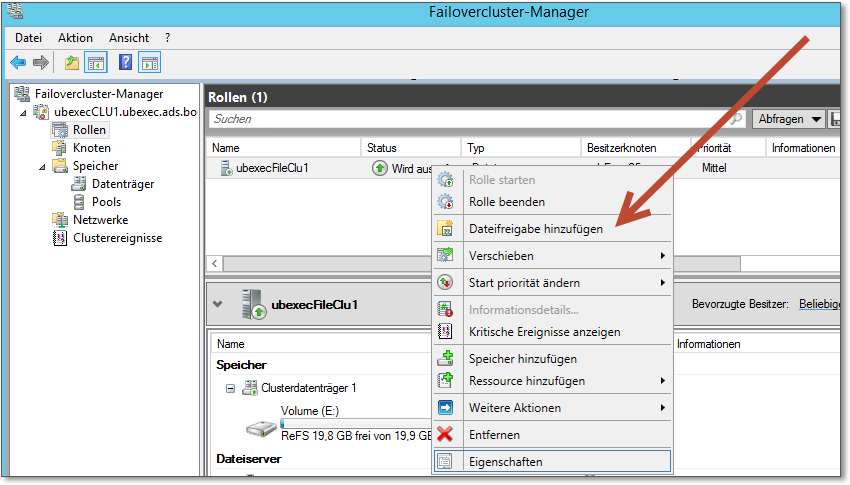
Abbildung 20.39 Jede Menge Menüpunkte: Zum Beispiel könnte man eine »Dateifreigabe hinzufügen«.
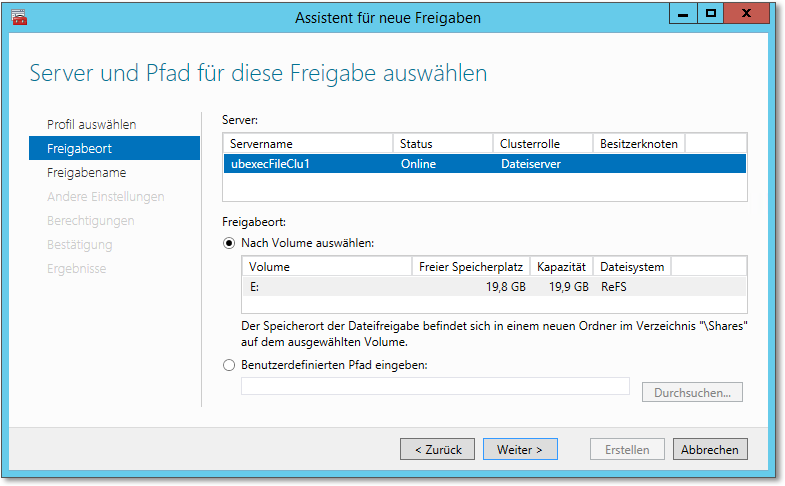
Abbildung 20.40 Geben Sie den Speicherort für den freigegebenen Ordner an.
20.2.4 Cluster schwenken
Die Idee hinter einem Failover-Cluster ist, dass beim Ausfall eines Knotens ein anderer dessen Aufgaben übernimmt. Das Schwenken des Clusters können Sie allerdings auch gezielt initiieren, beispielsweise um einen Knoten zu Wartungszwecken (z. B. zum Einspielen von Patches nebst fälligem Neustart) herunterzufahren, oder einfach, um zu probieren, ob ein anderer Knoten die Funktion übernehmen kann.
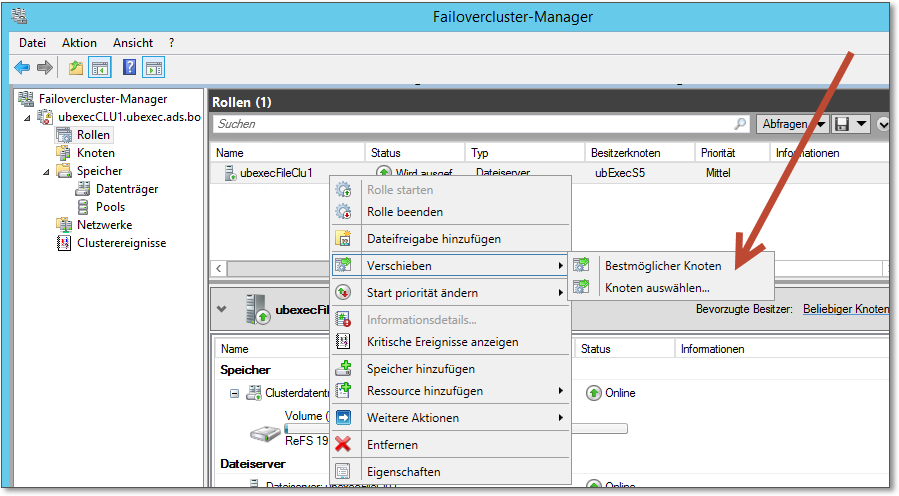
Abbildung 20.41 Der Dateiserver-Cluster kann geschwenkt werden ...
Im Eigenschaften-Dialog der Dienste bzw. Anwendungen findet sich der Menüpunkt Diesen Dienst oder diese Anwendung in einen anderen Knoten verschieben. In diesem Fall (Abbildung 20.41) ist zwar nur ein möglicher Knoten aufgeführt (der Cluster hat nur zwei Knoten), aber so wird’s gemacht.
In Abbildung 20.42 sehen Sie einen Zustand, der sich beim Verschiebevorgang ergibt: Die Ressourcen sind während des Verschiebens für kurze Zeit nicht im Zugriff. Die Clients können dann die Verbindung wieder aufbauen, sie ist aber in jedem Fall kurz »weg«.
Dies gilt übrigens auch beim Ausfall eines Knotens: Die Funktionalität wird zwar auf einen anderen Knoten verschoben, die Clients verlieren aber kurzzeitig die Verbindung. In den meisten Fällen ist das zwar kein Problem, Sie sollten sich aber darüber im Klaren sein!
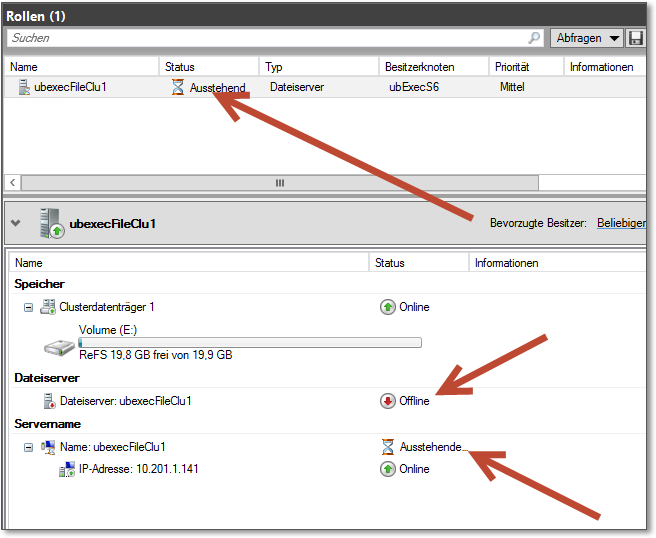
Abbildung 20.42 ... allerdings gibt es dabei eine kurze Funktionsunterbrechung für die Clients.
20.2.5 Feinkonfiguration des Clusters und weitere Vorgehensweise
Das Verwaltungswerkzeug für den Failover-Cluster hält viele, viele Konfigurationsmöglichkeiten bereit. Ich möchte diese hier nicht im Detail besprechen. Wenn Sie einen lauffähigen Cluster haben, sollten Sie in der Failover-Clusterverwaltung die Konfigurationsdialoge durchsehen und sich einen Überblick verschaffen. Die Optionen sind im Großen und Ganzen selbsterklärend, sodass seitenlange Beschreibungen in der Tat nicht notwendig sind.
Weiterhin möchte ich Ihnen dringend empfehlen, das Wiederherstellen des Clusters und einzelner Clusterknoten mit der von Ihnen verwendeten Sicherungssoftware auszuprobieren – und zwar in einer ruhigen Stunde und nicht erst, wenn der Notfall da ist.
20.2.6
Clusterfähiges Aktualisieren
Das Patchen von Systemen ist ein vordringliches Thema – das ist nun wirklich keine neue Erkenntnis. Natürlich ist das auch bei Clustern wichtig, wobei der Arbeitsprozess dabei in etwa dieser ist:
- Alle Ressourcen auf Knoten 2 schwenken.
- Knoten 1 aktualisieren.
- Alle Ressourcen auf den nun aktualisierten Knoten 1 schwenken.
- Knoten 2 aktualisieren.
- Fertig!
Das sind viele Handgriffe mit natürlich einigem Aktualisierungspotenzial. Microsoft hat mit Server 2012 das Clusterfähige Aktualisieren entwickelt. Abbildung 20.43 zeigt den Einstieg in diese Funktionalität.
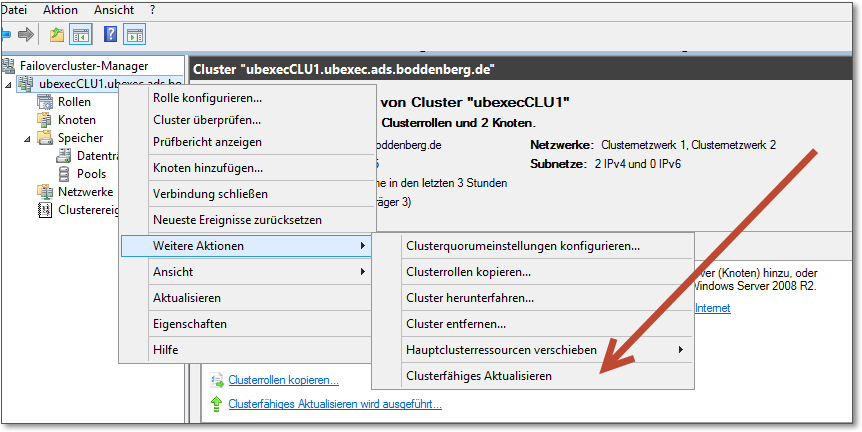
Abbildung 20.43 Eine spannende Option seit Server 2012: »Clusterfähiges Aktualisieren«
Abbildung 20.44 zeigt den Steuerungsdialog für Clusterfähiges Aktualisieren. Dieser Dialog gibt zunächst einen Überblick über den Update-Status des Clusters. Wie Sie sehen, ist das clusterfähige Aktualisieren noch nie gelaufen. Kann ja auch nicht, die Clusterressource ist noch nicht mal installiert.
Sie können sich beispielsweise einen Überblick darüber verschaffen, welche Updates auf den Clusterknoten benötigt werden. Die Updates kommen von dem konfigurierten WSUS-Server. Das Ergebnis zeigt der Dialog Vorschau der Updates anzeigen, der in Abbildung 20.45 zu sehen ist.
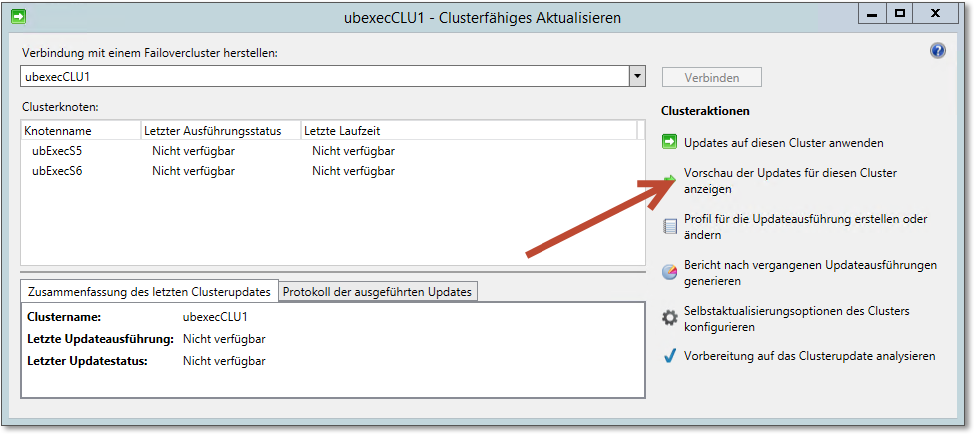
Abbildung 20.44 Der Steuerungsdialog für »Clusterfähiges Aktualisieren«
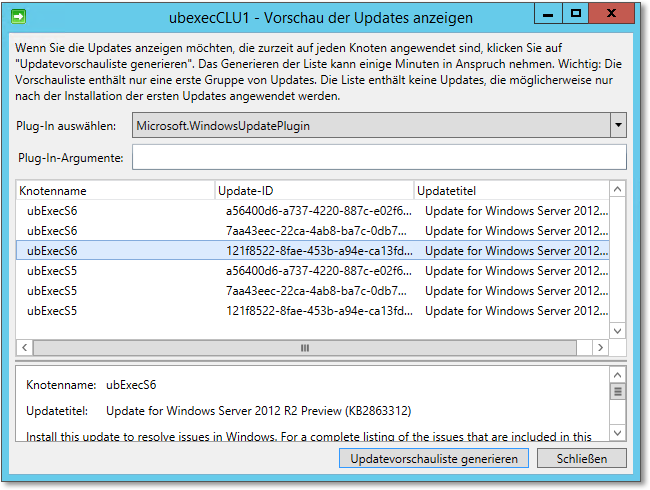
Abbildung 20.45 Die benötigten Updates
Damit das clusterfähige Aktualisieren funktioniert, muss die entsprechende Clusterrolle installiert werden. Das lässt sich per Mausklick im Steuerungsdialog initiieren, es startet der obligatorische Assistent. Abbildung 20.46 zeigt den ersten »wirklichen« Dialog des Assistenten: Ganz klar, wir wollen die Rolle dem Cluster hinzufügen.
Es können diverse Optionen gesetzt werden, die Sie in dem in Abbildung 20.47 gezeigten Dialog konfigurieren können. Die Optionen sind weitgehend selbsterklärend. Die wichtige Nachricht an dieser Stelle ist, dass Sie keine Optionen setzen müssen. Die Standardeinstellungen sind durchaus in Ordnung. Wichtig ist nur, dass man recht umfangreich in die Konfiguration eingreifen »könnte«.
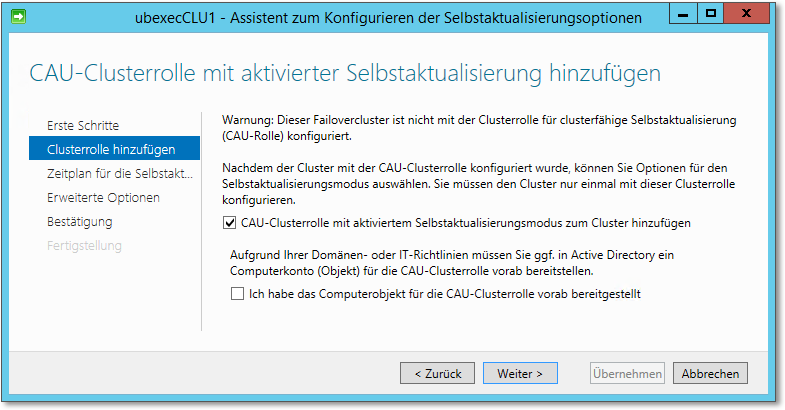
Abbildung 20.46 Installation der zugehörige Clusterrolle per Assistent
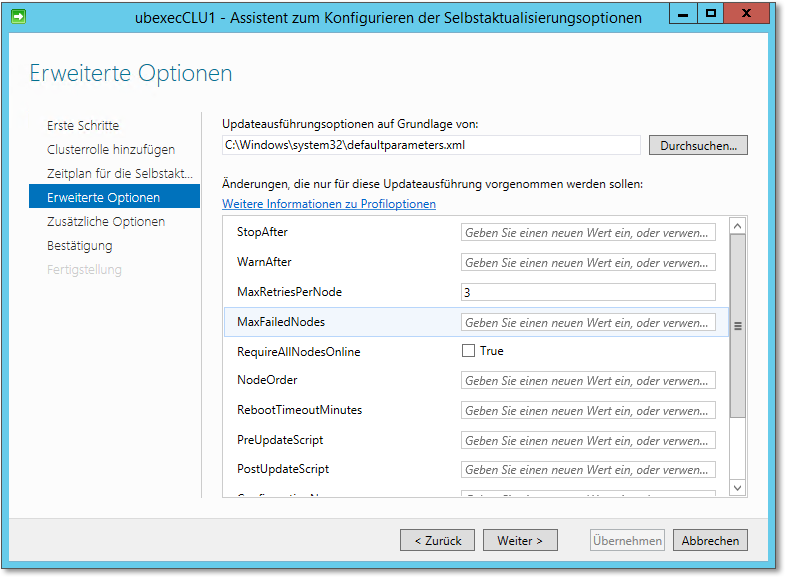
Abbildung 20.47 »Erweiterte Optionen« können, müssen aber nicht unbedingt gesetzt werden.
Abbildung 20.48 zeigt den laufenden Vorgang. Sie können im oberen Bereich des Dialogs erkennen, dass zunächst der eine Clusterknoten aktualisiert wird (auf dem Bild lädt er gerade die Updates herunter), während der andere in »Wartestellung ist«. Die aktiven Rollen sind auf den derzeit wartenden Knoten geschwenkt worden – er wartet also nur im Sinne des Update-Vorgangs, ansonsten ist er sehr aktiv.
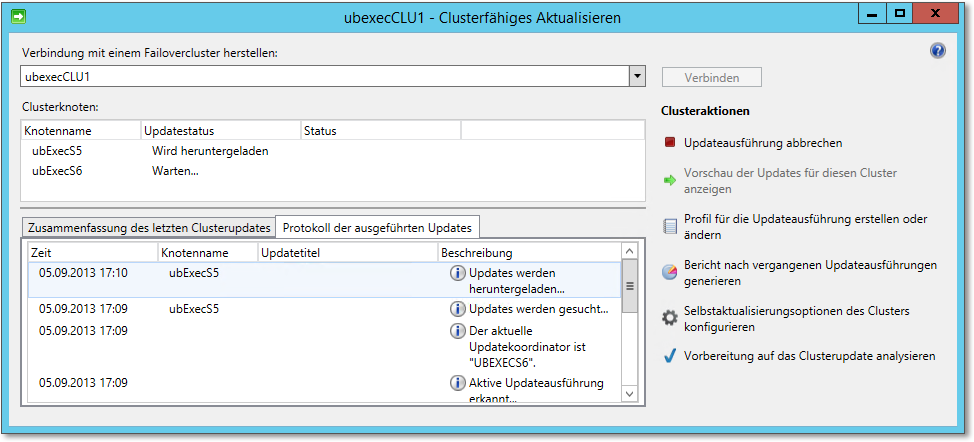
Abbildung 20.48 Hier läuft der Vorgang. Erst wird der eine Server »bearbeitet«, dann der andere.
Wenig überraschend ist, dass nach Abschluss des Updates des ersten Knotens geschwenkt wird, d. h., der frisch aktualisierte Knoten wird bezüglich der anderen Rollen der aktive Knoten, und der andere Clusterknoten wird aktualisiert.
Die beiden Clusterknoten des Demosystems laufen auf virtuellen Maschinen. Auf Abbildung 20.49 kann man erkennen, dass diese mit etwa 13 Minuten Zeitdifferenz neu gestartet worden sind. Das Update des zweiten Knotens hat also genau diese Zeit gedauert.
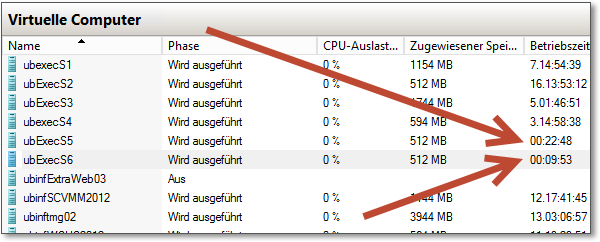
Abbildung 20.49 Da die Clusterknoten in diesem Beispiel virtualisiert laufen, kann man erkennen, dass sie mit 13 Minuten Zeitdifferenz neu gestartet wurden.
20.2.7
SQL Server 2012 installieren
Da der SQL Server ein Dienst ist, der häufig geclustert wird und die Installation etwas abweicht, führe ich diese kurz vor – ohne an dieser Stelle den Anspruch zu haben, eine detaillierte SQL-Anleitung zu liefern.
Sie müssen zunächst einen funktionsfähigen Cluster installieren. Anstatt dann den exemplarisch am Dateiserver-Cluster gezeigten Rollendienst zu installieren, machen Sie wie folgt weiter.
Installation des ersten Knotens
Um den ersten SQL-Clusterknoten zu installieren, führen Sie diese Schritte durch:
- Schnappen Sie sich den SQL Server-Installationsdatenträger, und lassen Sie das SQL Server-Installationscenter starten.
- Dort wählen Sie Option Neue SQL Server-Failoverclusterinstallation (Abbildung 20.50). Um es einmal ganz deutlich auszusprechen: Sie starten nicht die normale SQL-Installation.

Abbildung 20.50 Im SQL-Setup rufen Sie eine »Neue SQL Server-Failoverclusterinstallation« auf.
Hinweis
Wenn Sie mehrere Instanzen des SQL Server betreiben möchten, gehen Sie auch bei der zweiten und den folgenden Installationen vor, wie hier beschrieben. Sie beginnen dann ebenfalls mit einer Neuen SQL Server-Failoverclusterinstallation.
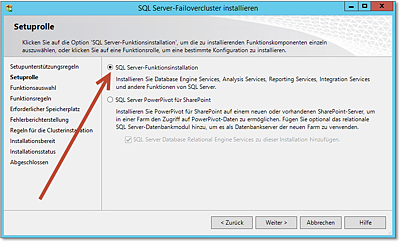
- Die erste Frage des Assistenten bezieht sich darauf, was überhaupt installiert werden
soll (Abbildung 20.51). Wählen Sie die SQL Server-Funktionsinstallation. Lassen Sie sich nicht davon irritieren, dass hier keine Rede von »Cluster« ist.
- In dem in Abbildung 20.52 gezeigten Dialog wählen Sie aus, was installiert werden soll. Auf jeden Fall wird
Database Engine Service benötigt, das ist die eigentliche Datenbank. Beachten Sie, dass Analysis Services und Reporting Services zwar auf Clusterknoten installiert werden können, sie sind aber trotzdem nicht geclustert.
Ich würde diese Dienste nach Möglichkeit nicht auf Clustern installieren.
Zu empfehlen wäre noch, in der Rubrik Freigegebene Funktionen die Verwaltungswerkzeuge zur Installation auszuwählen.
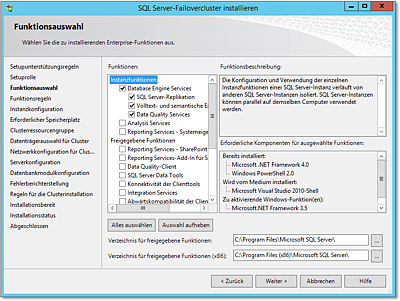
Abbildung 20.52 Für dieses Beispiel wird nur das Datenbankmodul installiert.
- Der in Abbildung 20.53 gezeigte Dialog wird jedem bekannt vorkommen, der bereits einen SQL Server aufgesetzt
hat. Es gibt aber einen kleinen Unterschied, nämlich das Feld Name des SQL Server-Netzwerks. Dahinter verbirgt sich der Name des SQL-Clusters. Anders gesagt, nach der Installation
wird ein Computerkonto dieses Namens vorhanden sein. Noch anders gesagt, diese Instanz
des SQL-Clusters wird unter diesem Namen vorhanden sein.
Sinnvollerweise entscheiden Sie sich für eine Standardinstanz. Hier eine benannte Instanz zu wählen, bedeutet höchstens Tipparbeit. Das Instanzstammverzeichnis wird nicht auf die Clusterdatenträger gelegt. Da dort keine Daten liegen werden, können Sie auch ruhig das Standardverzeichnis belassen.
- Der in Abbildung 20.54 gezeigte Dialog ist einfach, aber wirkungsvoll. In einer Clusterressourcengruppe werden die Ressourcen (wie Platten, IP-Adresse, Name, SQL Server etc.) zusammengefasst. Es ist sinnvoll, diese Clusterressourcengruppe wie den Cluster (Netzwerkname, siehe Abbildung 20.53) zu benennen.

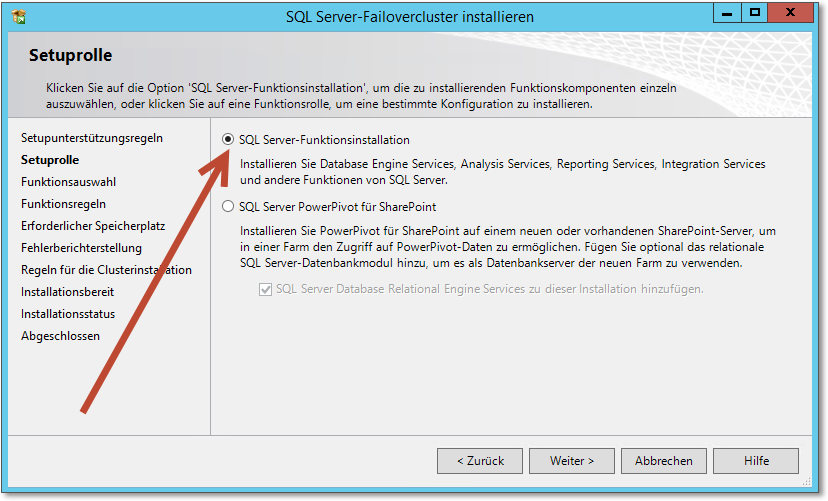
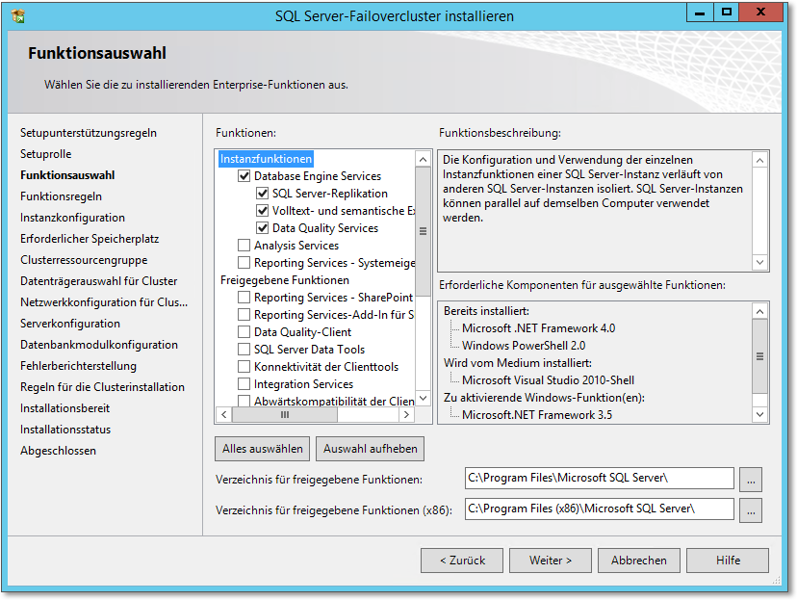
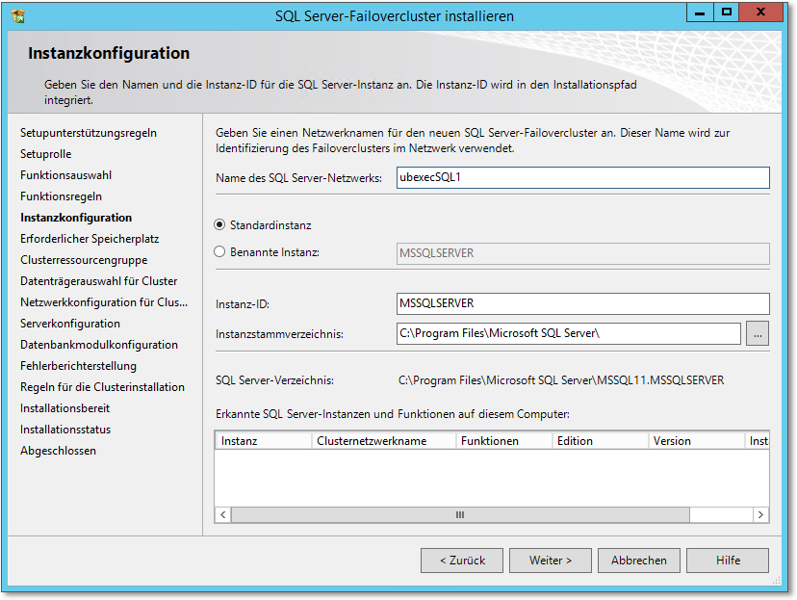
Abbildung 20.53 Interessant ist der Name des SQL-Clusters. Ansonsten empfiehlt sich die Installation einer »Standardinstanz«.
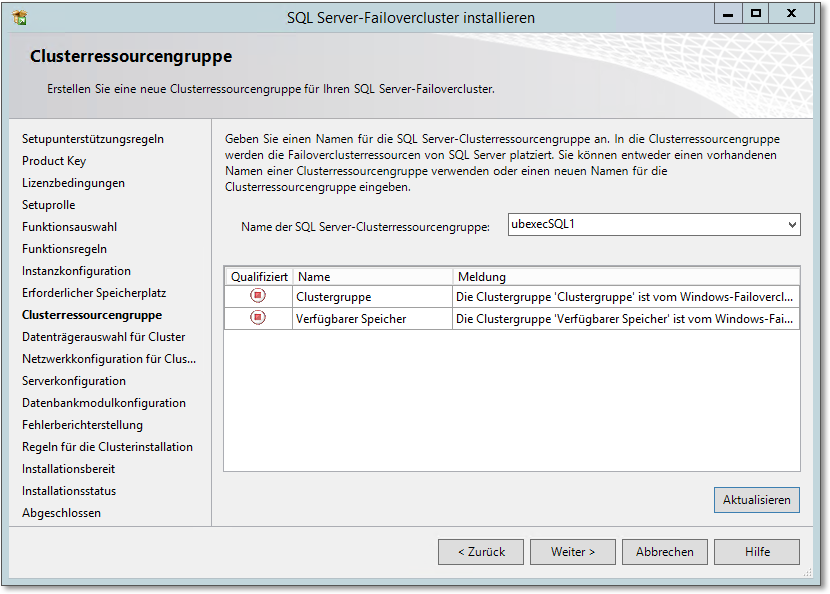
Abbildung 20.54 Erstellen Sie eine neue »Clusterressourcengruppe«.
Nun wird es mit der Zuweisung von Ressourcen ernst:
- In Abbildung 20.55 sehen Sie den Dialog für die Zuweisung von Clusterdatenträgern, die zuvor angelegt
worden sein müssen. Sie können einfach die Datenträger anhaken, die für diese Clusterinstanz
verwendet werden sollen. Wenn Datenträger nicht zur Auswahl stehen, beispielsweise
weil sie schon von anderen Clusterressourcen oder für das Quorum verwendet werden,
wird das mit einer kurzen Erläuterung angezeigt.
Beachten Sie: Wenn Sie mehrere SQL-Cluster (also Instanzen) auf dem Cluster installieren möchten, benötigen diese jeweils eigene Datenträger.
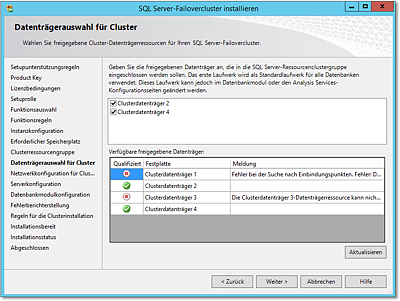
Abbildung 20.55 Wählen Sie die Datenträgerressourcen für den neuen SQL-Cluster.
- Dem neuen SQL-Cluster muss dann noch eine IP-Adresse zugewiesen werden, was Abbildung 20.56 zeigt.
- Als Nächstes werden die Dienstkonten zugewiesen (Abbildung 20.57). Hier müssen Sie Domänenkonten verwenden. Diese Konten brauchen Sie nicht mit »besonderen
Rechten« auszustatten – das erledigt das SQL-Setup für Sie.
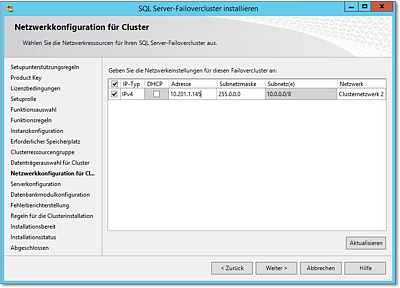
Abbildung 20.56 Zuweisen der IP-Adresse
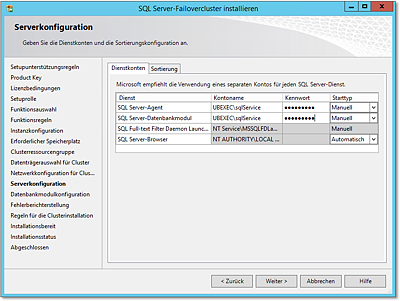
Abbildung 20.57 Angeben der Dienstkonten. Es müssen Domänenkonten verwendet werden.
Hinweis
Beachten Sie, dass SQL Server es bei Domänenkonten aus Berechtigungsgründen nicht schafft, automatisch die SPNs zu registrieren (SPN = Service Principal Name). Sie müssen die SPNs entweder manuell anlegen oder eine generelle Berechtigung im AD setzen. Mehr Infos gibt es hier: http://technet.microsoft.com/de-de/library/ms191153.aspx#Auto
- Nun müssen im auf Abbildung 20.58 gezeigten nächsten Dialog die Datenverzeichnisse eingerichtet werden. Diese Pfade müssen auf Clusterdatenträger verweisen.
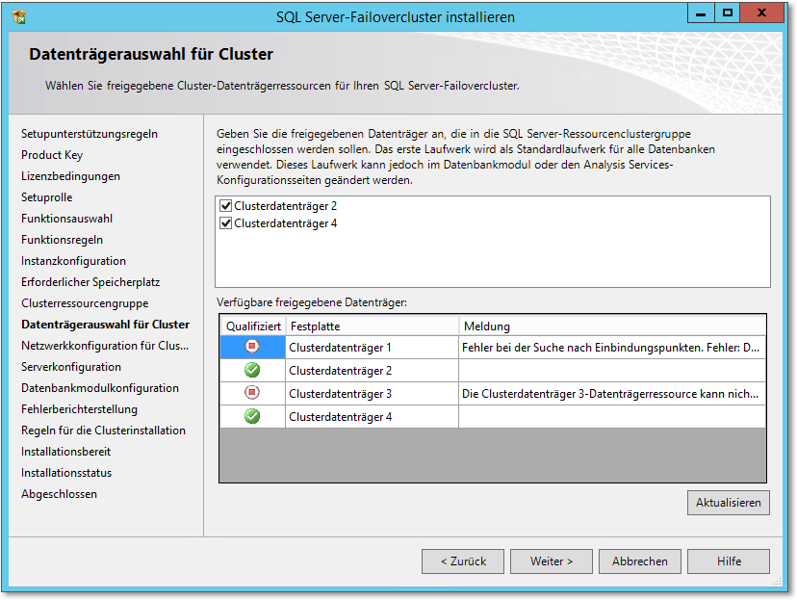
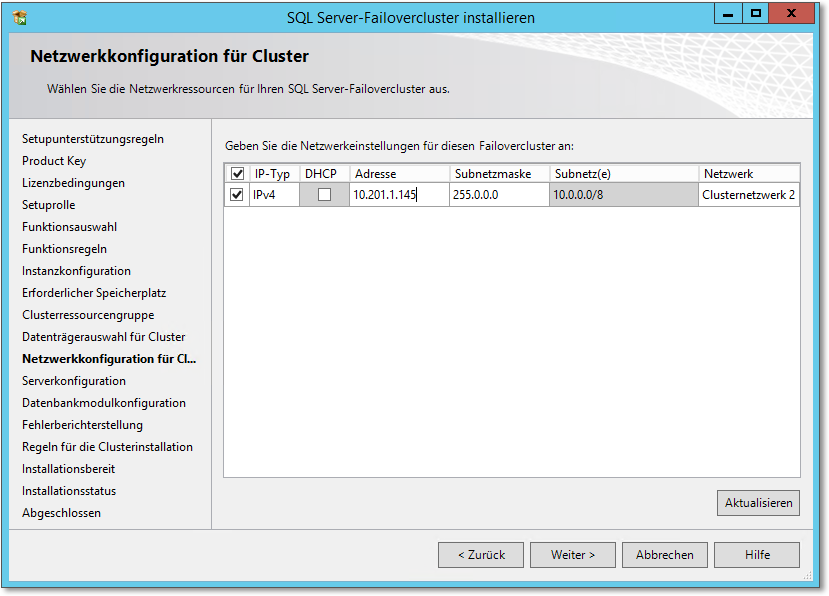
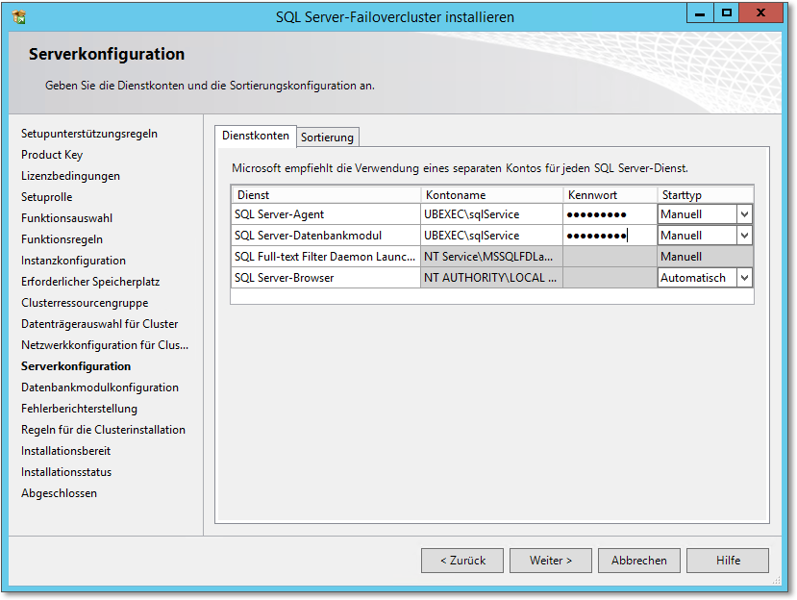
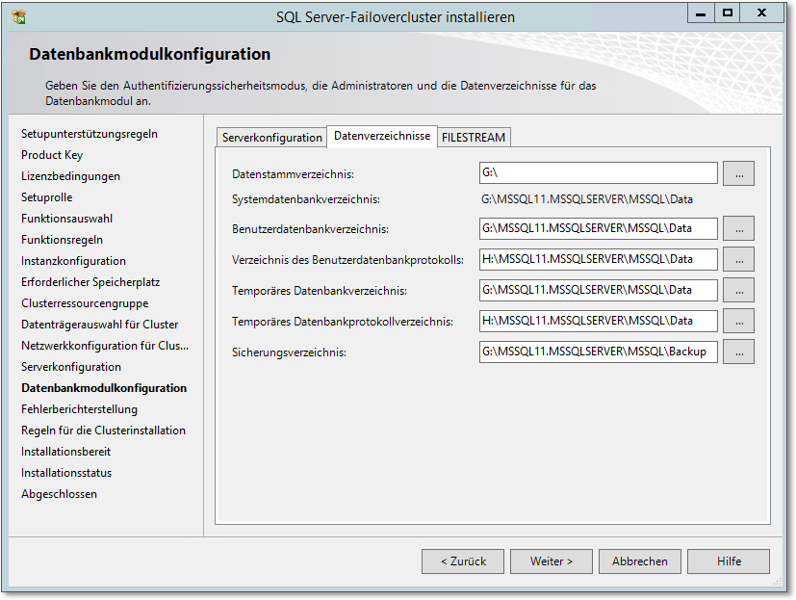
Abbildung 20.58 Hier werden die Datenverzeichnisse eingerichtet.
Hinweis
Auch wenn der SQL Server auf einem Cluster liegt: Er ist nicht automatisch schnell. Der entscheidende Faktor für die SQL Server-Performance sind Platten – und zwar sowohl die Anzahl und der RAID-Level als auch Faktoren wie die Blockgröße oder das Alignment. Sie müssen also auch beim Cluster die »Sizing-Hausaufgaben« sorgfältig erledigen.
Wenn, wie in Abbildung 20.59 gezeigt, alles auf »Grün« steht, ist der erste Schritt getan. Sie haben nun einen funktionsfähigen Ein-Knoten-SQL-Cluster, der übrigens schon funktionsfähig ist – nur eben nicht redundant. Wie man die weiteren Knoten zu SQL-Clusterknoten macht, zeigt der nächste Abschnitt.
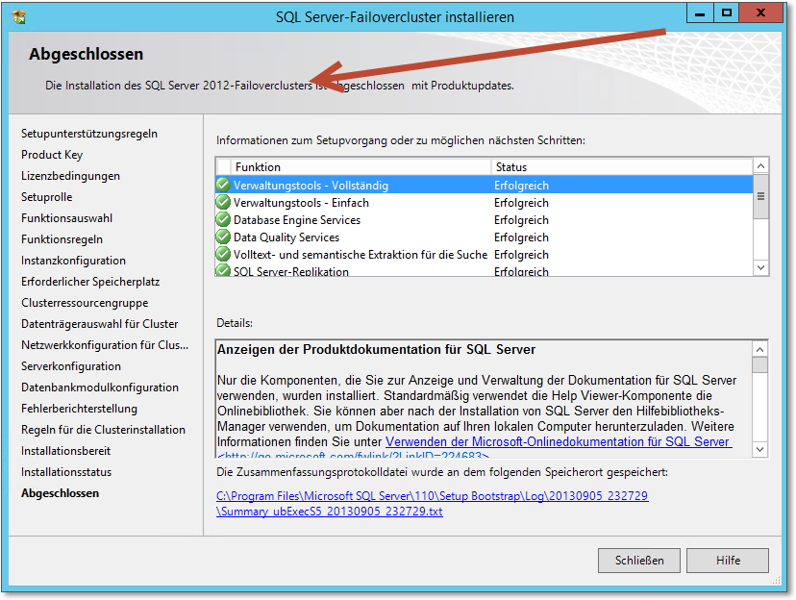
Abbildung 20.59 Der SQL-Failover-Cluster ist erstellt – alles im grünen Bereich!
Zweiter und alle weitere Knoten
Nun müssen noch die weiteren Knoten des zukünftigen SQL-Clusters mit SQL Server ausgerüstet werden.
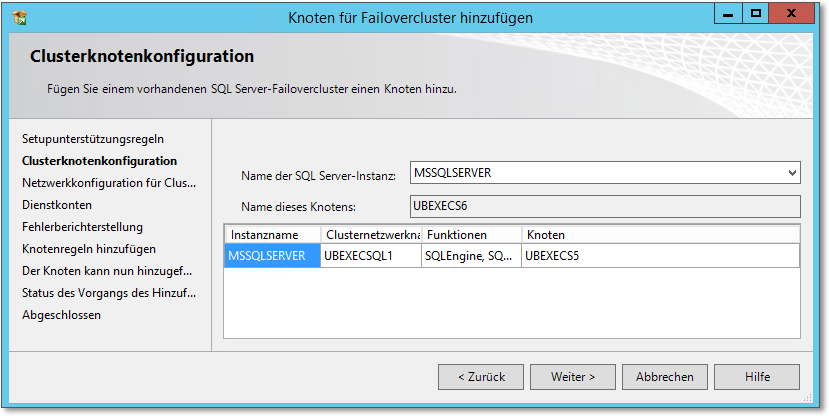
Der »Trick« ist im Grunde genommen, auf den weiteren Knoten im SQL Server-Installationscenter den Menüpunkt Knoten einem SQL Server-Failovercluster hinzufügen auszuführen (Abbildung 20.60). Die Installation ist nicht aufregend kompliziert, es müssen nur wenige Einstellungen getroffen werden.
- Die erste Entscheidung ist, welchem SQL-Failover-Cluster der Knoten hinzugefügt werden
soll. Dies wird in dem auf Abbildung 20.61 gezeigten Dialog erledigt. Beachten Sie, dass es in einem (Windows-)Cluster mehrere
SQL-Cluster (Instanzen) geben kann. Der Dialog ergibt also Sinn.
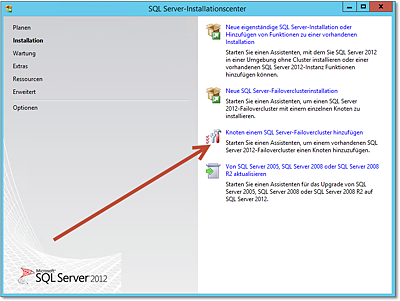
Abbildung 20.60 Diese Option führen Sie auf allen weiteren Knoten aus.
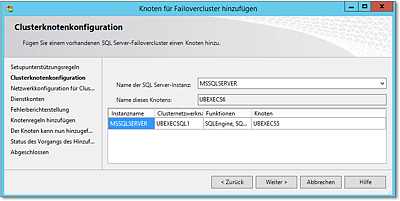
Abbildung 20.61 Auswahl des SQL-Clusters, dem der Knoten hinzugefügt werden soll
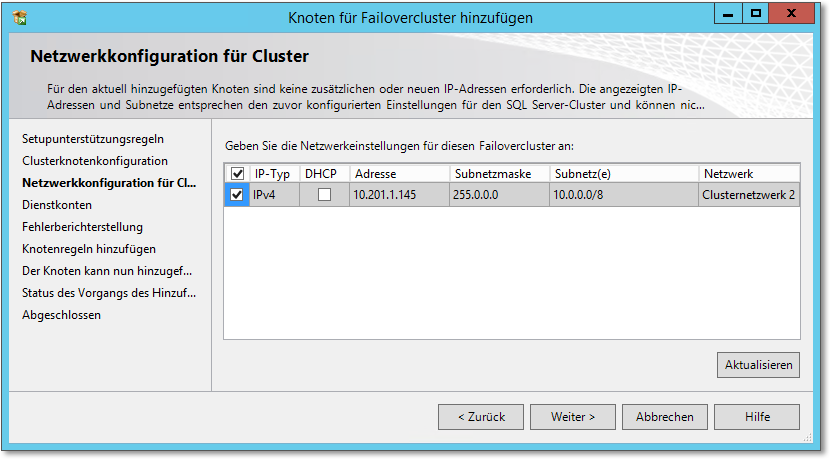
- In Abbildung 20.62 sehen Sie die Konfiguration der Netzwerkeinstellungen. Sie selektieren hier das zu
verwendende Clusternetzwerk. Vermutlich ist, zumindest in einer kleineren Installation,
hier ohnehin nur ein Clusternetzwerk vorhanden.
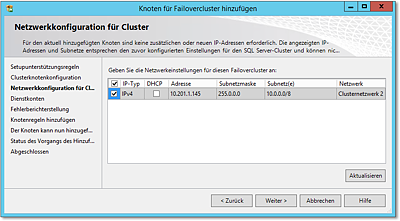
Abbildung 20.62 In der Netzwerkkonfiguration müssen Sie die zu verwendenden Netze selektieren.
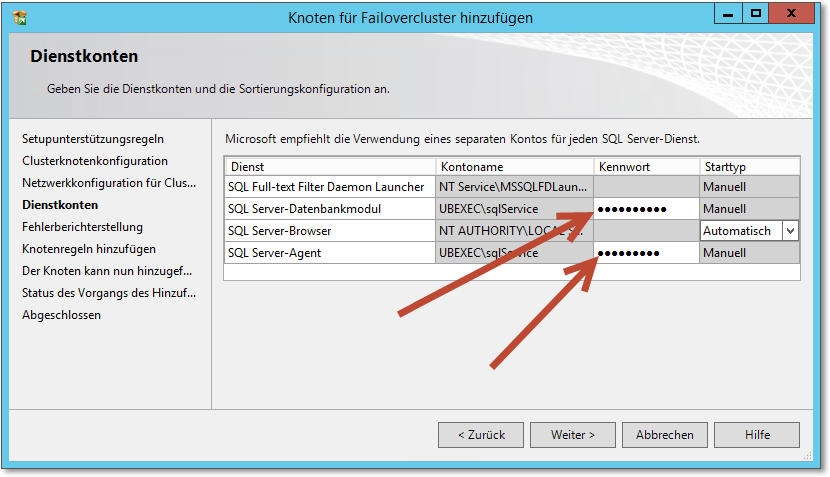
- Abbildung 20.63 zeigt den Dialog zur Eingabe der Kennwörter der Dienstkonten. Da der SQL-Cluster
ja auf diesem Knoten laufen soll, müssen die Dienstkonten nebst Kennwörtern gespeichert
werden.
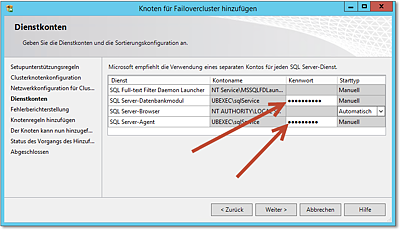
Abbildung 20.63 Die Kennwörter der Dienstkonten müssen eingegeben werden.
An dieser Stelle wird auch klar, warum die Dienstkonten Domänenkonten sein müssen: Damit dasselbe Dienstkonto auf verschiedenen Clusterknoten vorhanden ist, geht das nur mit Domänenkonten – hinter dem Konto Netzwerkdienst steht letztendlich das Computerkonto, und das wäre auf den verschiedenen Servern bzw. Clusterknoten jeweils ein anderes Konto.
Nach Abschluss des Installations-Assistenten steht der Clusterknoten zur Verfügung.
Ihre Meinung
Wie hat Ihnen das Openbook gefallen? Wir freuen uns immer über Ihre Rückmeldung. Schreiben Sie uns gerne Ihr Feedback als E-Mail an kommunikation@rheinwerk-verlag.de.

 Jetzt Buch bestellen
Jetzt Buch bestellen



